xcore.ai VPU
xcore.ai拥有一个矢量处理单元(VPU)。这是一种专用的硬件,用于通过使应用程序能够在每个指令中执行更多的工作来加速DSP和其他数学运算。
XS3 ISA中针对VPU的所有指令都是单线程周期指令。
接下来的大部分内容提供了关于xcore.ai VPU行为的相当低级的细节。它旨在为用户提供足够的背景,以了解VPU适用于哪些类型的操作。
如果您主要关注这些细节如何影响您作为lib_xcore_math的用户,请随意跳到后面。
VPU寄存器
VPU有4个关联的寄存器,分别为vR、vD、vC和vCTRL。
每个硬件线程(xcore.ai上每个tile有8个线程)都有自己的一组矢量寄存器。每个线程可以独立地使用VPU,而且线程之间没有竞争或干扰。
vCTRL
vCTRL是一个12位的寄存器,其内容如下:
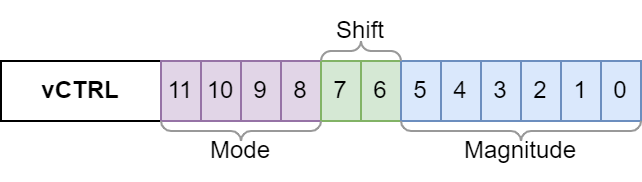
Mode字段控制在指令执行期间如何解释矢量寄存器的内容。有效的模式有32位(VSETCTRL_TYPE_INT32)、16位(VSETCTRL_TYPE_INT16)和8位(VSETCTRL_TYPE_INT8)。某些指令仅在32位模式下可用。
主要是Mode决定要使用的算术的位深度。例如,VLMUL指令将使用模式位来确定应用的是8位、16位还是32位乘法。它还将确定用于饱和指令的饱和边界。
Shift字段控制多个指令(VLADSB、VFTFB、VFTFF、VFTTB、VFTTF)使用的移位行为。具体来说,它允许这些操作的结果向左或向右移动一位(或不移动)。在执行FFT时,这对于有效地管理头空间非常有用。
Magnitude字段保存矢量的头空间的表示。当使用VSTR、VSTD或VSTC指令(但不是VSTRPV)将矢量寄存器的内容存储到内存中时,该字段将更新以反映底层整数的大小。从该字段检索的值是存储到内存中的最大幅度整数所需的位数。
矢量寄存器
有三个矢量寄存器,vR、vD和vC。每个寄存器的宽度为32字节,根据使用的VPU指令的不同,每个寄存器都有特定的用途。
矢量寄存器的内容的解释取决于配置的VPU模式和所使用的指令。
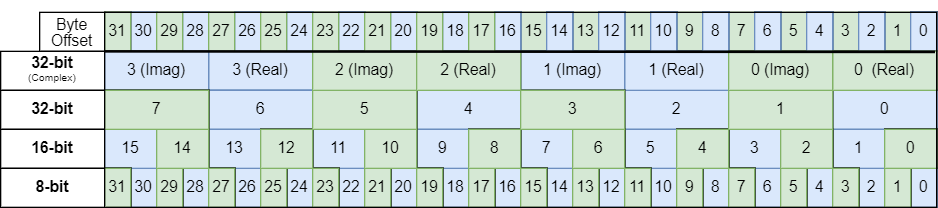
对于大多数VPU指令,在32位模式下,矢量寄存器的内容将��被解释为8个int32_t值。在16位模式下,解释为16个int16_t值。在8位模式下,解释为32个int32_t值。例如,VLADD、VLMUL和VLASHR指令会这样解释寄存器的内容。
在32位模式下,有几个指令将矢量寄存器的内容解释为具有4个复数值的复数值,每个复数值由32位实部和32位虚部组成。例如,VCMR、VCMI和VFTFF指令就是这样做的。
从概念上讲,可以将矢量寄存器视为如下模型,其中使用的字段类型取决于VPU模式。
union {
complex_s32_t c32[4];
int32_t s32[8];
int16_t s16[16];
int8_t s8[32];
} vector_register_t;
vector_register_t vR, vD, vC;
vector_register_t联合类型实际上在任何地方都没有定义。这只是一个概念模型。
此外,几个VPU指令(VLMACC、VLMACCR、VLSUB)将vD和vR这对矢量寄存器视为具有比配置模式更高位深度的_累加器_。
累加器
上述提到的累加指令将vD和vR作为单个逻辑寄存器处理,通常写为vD:vR。在这种情况下,来自vD的元素与来自vR的相应元素按位连接(其中vD占据最高位),形成累加器元素。
8位和16位模式
在8位和16位模式下,共有16个累加器,每个累加器的�位深度为32位。需要明确的是,在8位模式下,有16个32位累加器可用,而不是32个16位累加器。
从概念上讲,在8位和16位模式下,vD:vR矢量累加器数据结构如下(其中vD[k]和vR[k]各自为16位):

请注意,在这种情况下,可以将vR[k]视为一个无符号的16位整数。这是有符号整数的二进制补码编码的直接结果。
例如,int16_t x = -12345存储为以下位序列
1 1 0 0 1 1 1 1 1 1 0 0 0 1 1 1 = -12345 = x
该序列是以下两个值的直接和
1 1 0 0 1 1 1 1 0 0 0 0 0 0 0 0 -12544 = ( int16_t) (x & 0xFF00)
- 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 1 + 199 = + (uint16_t) (x & 0x00FF) -------------------------------- = ------ ----------------------- 1 1 0 0 1 1 1 1 1 1 0 0 0 1 1 1 -12345 = ( int16_t) (x & 0xFFFF)
这种方式有时对于解决需要无符号结果的问题很有用。
32位模式
在32位模式下,有8个累加器,每个累加器的位深度为40位。这意味着无法在VPU中表示两个32位数的完整、精确的64位乘积。与8�位和16位模式类似,累加器存储在vD和vR之间。
请注意,虽然累加操作将在40位边界处_饱和_,但仍将使用完整的_64_位来表示累加器。在32位模式下进行累加时,有符号的40位结果在每个vD[k]的最高24位中进行符号扩展。

没有任何复杂的32位指令会使用vR和vD作为累加器。复杂操作的分量位深度始终为32位。
VPU操作
XS3 ISA中的大多数指令执行单个简单操作,而针对VPU的指令通常执行更复杂的操作。单个指令可能会执行以下任何或所有操作:
- 加载32字节矢量
- 对元素进行逐个乘法运算
- 对矢量元素应用位移操作
- 对元素进行逐个加法运算
- 应用舍入逻辑
- 应用饱和逻辑
- 对累加器进行循环移位
事实上,VLMACCR指令(在单个线程周期内执行)执行所有这些操作以及其他操作。
内存访问
有少数几个VPU指令直接从主存中加载或写入数据。这些指令包括仅从内存加载向量(例如VLDR、VLDD),仅将向量写入内存(例如VSTC、VSTRPV),以及在加载数据后原子地从内存中加载并操作数据(例如VLMUL、VLMACCR)。
在所有情况下,从内存加载或写入的VPU指令要求使用的基地址为字(4字节对齐)。这适用于32位、16位和8位模式。
因此,lib_xcore_math的许多函数在操作其输入的向量(包括绑定到块浮点向量的数组)时都要求向量以字对齐的地址开始。某些API函数还要求8字节对齐(这种更严格的对齐要求是由于使用STD或LDD非VPU指令)。
使用lib_xcore_math的API时,请确保检查每个操作的文档,以确保向量使用正确的对齐方式。该库还提供了方便的宏,可以在声明数组时使用,以确保具有所需的对齐方式。
位移和舍入
除了8位和16位模式下的VLMACC和VLMACCR之外,VPU执行的所有乘法都会在硬件中应用一个不可避免的舍入算术右移。
| 模式 | 右移位数 |
|---|---|
N位 | N-2位 |
| 8位 | 6位 |
| 16位 | 14位 |
| 32位 | 30位 |
这实际上意味着VLMUL指令(以及所有32位乘法)是_定点_乘法。VLMUL指令从指定内存地址加载元素的矢量,逐个将其与vR的内容相乘,然后应用舍入位移(随后是饱和逻辑),并用结果替换vR的内容。
有了这个定点的框架,这意味着8位、16位和32位模式下的乘法的乘法恒等元素分别为0x40、0x4000和0x40000000。
这也意味着,如果x是在发出VLMUL指令之前vR[k]的值,并且y是之后vR[k]的值,那么以下关系必须始终成立:
换句话说,VLMUL指令 不能 用于将值按小于-2的因子缩放,且缩放因子始终严格小于2。这对所有模式都是正确的。
舍入逻辑与位移一起应用。舍入是远离零的。
以16位模式为例。由于对乘积应用了14位右移,从概念上讲,这意味着vR的初始内容或从内存加载的值的矢量可以被视为使用Q2.14格式的定点值。等效地,vR和从内存加载的值的矢量可以被视为使用Q9.7定点格式。
假设vR[0]的初始值为0x1234。如果发出VLMUL指令,从内存加载的值矢量t[],其中t[0] = 0x22222,将发生以下情况(因为VLMUL逐个操作元素,除了索引0的元素外,其他元素都可以忽略):
vR[0] = 0x1234
t[0] = 0x2222 // 从内存加载
P = vR[0] * t[0] = 0x026D52E8 // 32位乘积
Q = P >> 14 = 0x09B5.4BA0 // 14位右移(注意小数点)
R = round(Q) = 0x09B5 // 应用舍入逻辑(向下舍入)
S = sat16(R) = 0x09B5 // 应用饱和逻辑(无饱和)
vR[0] <-- 0x09B5 // 赋值回vR[0]
饱和
xcore.ai上的大多数VPU操作都应用饱和逻辑到输出值。饱和逻辑通过将任何大于上饱和边界的结果夹在上界上,将任何小于下饱和边界的结果夹在下界上,避免算术溢出。
XS3 VPU还使用_对称_饱和边界,即下饱和边界是上饱和边界的负数。这与使用完整的二进制�补码范围作为可能的输出值相比是相反的。这样留下了一个无法输出的值。
| 结果深度 | 下饱和边界 | 上饱和边界 | 无法输出 |
|---|---|---|---|
| 40位 | 0x7FFFFFFFFF | -0x7FFFFFFFFF | -0x8000000000 |
| 32位 | 0x7FFFFFFF | -0x7FFFFFFF | -0x80000000 |
| 16位 | 0x7FFF | -0x7FFF | -0x8000 |
| 8位 | 0x7F | -0x7F | -0x80 |
应用饱和逻辑的理由是,饱和通常比允许整数溢出更可取。此外,使用_对称_饱和边界的理由是,例如,值-0x8000(在16位模式下)并不总是表现良好。
例如,对于int32_t值,-0x80000000 = INT32_MIN = -INT32_MIN。也就是说,INT32_MIN和0都等于它们自己的负数,因为0x80000000 = INT32_MAX + 1是-0x80000000在二进制补码中的实际_编码_。
即使XS3 VPU无法从任何算术操作中_输出_值-0x80000000,但当作为_输入_时,-0x80000000是可以正确处理的。例如,当发出VLADD指令时,如果vR[0]是-0x80000000,或者从内存加载的某个元素是-0x80000000,都是如此。
当使用VLDR、VLDD或VLDC指令将矢量从内存加载到矢量寄存器时,XS3 VPU不会应用饱和逻辑。在写入内存时也不会应用饱和逻辑。
然而,在使用VLASHR指令将值从内存加载到vR时,有时需要使用饱和逻辑。VLASHR指令从内存加载矢量,应用有符号算术右移(由寄存器指定),进行饱和,然后将结果放入vR。即使指定的移位为0位,此指令也会进行饱和。
头空间跟踪
VPU的vCTRL寄存器中的Magnitude位用于检测矢量的头空间。每当使用VSTR、VSTD或VSTC指令将其相应矢量寄存器的内容写入内存时,都会更新vCTRL。VPU检查正在写入的每个元素中的非符号位数以及vCTRL中的Magnitude位的当前值。vCTRL中的Magnitude位将更新为这些值中的_最大值_。
这个过程不会发生在VSTRPV指令中。
使用此机制,可以通过简单地迭代矢量、将其加载到矢量寄存器并将其存储回内存来确定矢量的头空间。在迭代之前,使用VSETC指令将Magnitude位清零为0,在迭代之后,使用VGETC指令检索Magnitude位。矢量的头空间是31、15或7减去Magnitude位,具体取决于是否在32位、16位或8位模式下。
当执行输出矢量的算术操作时,此机制还可以免费确定头空间。使用相同的过程,在操作之前和之后分别清除和检索Magnitude位,以确定矢量的头空间。
在操作过程中,有时必须将中间值写入内存。在这种情况下,应谨慎�使用VSTR、VSTD或VSTC指令将中间结果写入内存,因为这可能会破坏vCTRL中的Magnitude位。在这种情况下,通常可以使用VSTRPV指令来绕过对vCTRL的更新。
lib_xcore_math中的VPU逻辑
lib_xcore_math的各种API将用户与详细的VPU行为隔离开来。然而,根据所使用的特定API和函数,其中的一些细节不可避免地会显现在用户的范围内。
内存对齐
其中最重要的问题是VPU的内存对齐要求。所有VPU加载和存储操作必须对齐到内存对齐的地址。这最终意味着用户分配的任何向量(静态或动态分配)也必须满足此条件。
在XS3上,字的大小为32位,因此字对齐是4字节对齐。换句话说,VPU加载的任何地址x的两个最低有效位必须为零,满足以下条件:
((x & 0x3) == 0)
对于32位值,这通常不是问题,因为工具链已经保证了(简单的)int32_t标量和数组的分配是字对齐的。此外,使用malloc()分配的内存保证是8字节对齐的。然而,对于8位和16位向量,通常不能保证字对齐。此外,许多API函数不仅要求字对齐,还要求双字(8字节)对齐。
为了帮助用户处理这些要求,lib_xcore_math提供了一对宏,可以用于强制字对齐或双字对齐。这些宏是WORD_ALIGNED和DWORD_ALIGNED。
这些宏在声明变量时使用,例如:
int32_t DWORD_ALIGNED someValA;
int32_t WORD_ALIGNED someValB[13];
int8_t WORD_ALIGNED someValC[100];
int16_t DWORD_ALIGNED someValD[22];
强烈建议使用`lib_xcore_math` API的用户使用这些宏对任何数组(包括`int32_t`)进行注释,这些数组将用作API的输入(包括绑定到块浮点向量的数组)。用户还被敦促仔细检查文档,以确定是否需要双字对齐。
当不满足对齐要求时,将引发`ET_LOAD_STORE`异常。
头空间报告
在使用lib_xcore_math的向量API时,特别是在调用“prepare”函数时,通常需要向量头空间作为输入。在需要时,调用方有责任跟踪向量的头空间。
为了帮助用户进行此操作,并避免不必要的显式头空间计算(因为通常是免费的),大多数向量API的操作(或者至少是输出向量的操作)将返回一个headroom_t值。此值是输出向量的计算头空间。
在使用BFP API时,向量头空间(除非另有说明)将由API跟踪。
位移行为
最后,在使用向量API时,大多数应用算术逻辑的函数都要求用户提供一个或多个right_shift_t类型的_移位_参数。这些移位参数的类型定义在right_shift_t中。
这些移位参数的需求是由以下几个问题导致的:
- 在乘法或累加时避免位深度增长,
- 避免由VPU的硬件右移引起的算术下溢出,
- 确保块浮点指数正确计算。
最终,这是为了避免溢出,同时尽可能保持更多的算术精度。
为了帮助处理这个问题,向量API中的大多数算术操作都有一个伴随函数(称为“prepare”函数),按照惯例,其名称是操作函数的名称后面附加了“_prepare”。“prepare”函数的目的是使用有关操作的输入向量(如指数、头空间以及有时长度)的元数据,并返回与操作的输出尾数关联的适当输出指数(用于输出尾数)以及操作所需的任何位移。
例如,vect_complex_s32_macc()是一个实现32位复数逐元素乘积累加的操作。
C_API
headroom_t vect_complex_s32_macc(
complex_s32_t acc[],
const complex_s32_t b[],
const complex_s32_t c[],
const unsigned length,
const right_shift_t acc_shr,
const right_shift_t b_shr,
const right_shift_t c_shr);
b[]和c[]是输入向量,acc[]是输入/输出向量。此函数将b[]和c[]的元素逐个相乘,并将结果添加到acc[]的相应元素中。为此,需要_3_个移位参数。
acc_shr、b_shr和c_shr对应于acc[]、b[]和c[],它们是_输入_移位。在乘法之前,b_shr和c_shr是应用于b[]和c[]的元素的有符号算术右移(在乘法之前)。因为执行32位乘法,VPU还会对乘积应用30位的算术右移。然后将acc_shr应用于acc[]的元素,然后将其添加到中间结果中。
vect_complex_s32_macc_prepare()是vect_complex_s32_macc()的相应准备函数。
C_API
void vect_complex_s32_macc_prepare(
exponent_t* new_acc_exp,
right_shift_t* acc_shr,
right_shift_t* b_shr,
right_shift_t* c_shr,
const exponent_t acc_exp,
const exponent_t b_exp,
const exponent_t c_exp,
const exponent_t acc_hr,
const headroom_t b_hr,
const headroom_t c_hr);
vect_complex_s32_macc_prepare()接受所有三个输入向量的指数和头空间,并输出结果的指数以及所需的三个移位参数。
用户必须仔细注意这些移位参数在所调用的函数中的使用方式。有时移位应用于_输入操作数_,而其他时候移位应用于中间结果以产生_输出_。此外,有时操作使用_有符号_右移(典型的_输入_移位),这意味着它们可以用于左移元素(避免下溢)。但有时操作使用_无符号_移位(典型的_输��出_移位)。
向量API应被视为用于高级用法的低级API。在调用API时,一定要参考文档,以确定对于给定的API调用,移位参数的确切使用方式。