Mixed-Precision Vector API
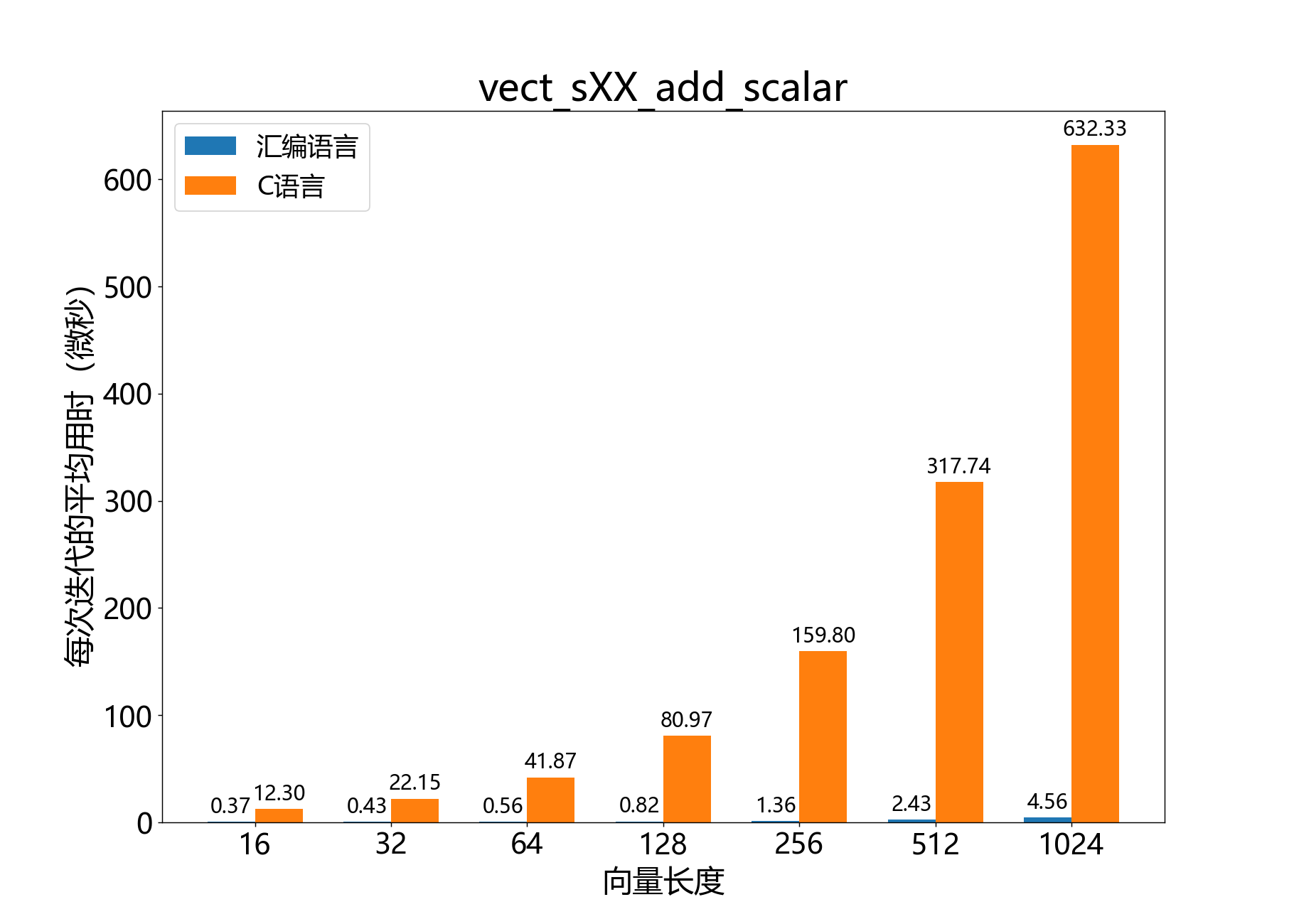
void mat_mul_s8_x_s16_yield_s32()
将一个8位矩阵乘以一个16位向量,得到一个32位结果向量。
该函数将一个8位 矩阵 乘以一个16位的 元列向量 ,并将结果作为一个32位的 元向量 返回。
参数:
-
int32_t output[]– [inout] 输出向量 -
const int8_t matrix[]– [in] 权重矩阵 -
const int16_t input_vect[]– [in] 输入向量 -
const unsigned M_rows– [in] 矩阵 的行数 -
const unsigned N_cols– [in] 矩阵 的列数 -
int8_t scratch[]– [in] 该函数使用的需要字对齐的缓冲区
异常:
ET_LOAD_STORE如果matrix或input_vect不是字对齐的(请参阅 笔记:向量对齐)
参考性能:
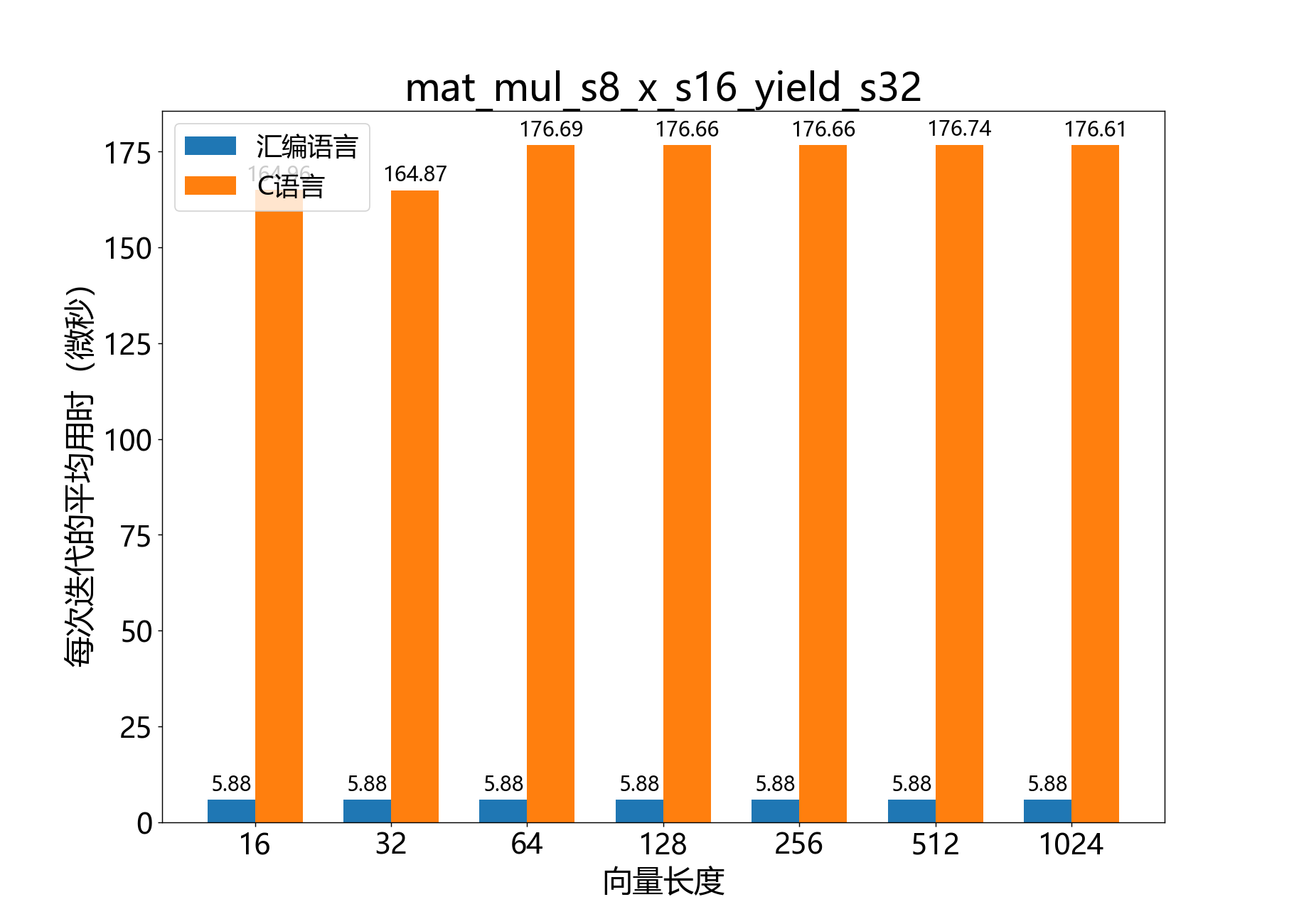
unsigned vect_sXX_add_scalar()
向向量添加标量。
向向量添加标量。适用于8位、16位或32位的实数或复数。
length_bytes 是要输出的总字节数。因此,对于16位向量,length_bytes 是元素数量的两倍,而对于复数32位向量,length_bytes 是元素数量的8倍。
c 和 d 是用于填充内部缓冲区的值,将其添加到输入向量中,规则如下:在内部分配一个8个字(32字节)的缓冲区(在堆栈上)。偶数索引的字填充为 c,奇数索引的字填充为 d。对于实数向量,c 和 d 应该是相同的值 - d 的原因是为了使这个函数也适用于复数32位向量。这也意味着对于16位向量,需要将要添加的值复制到字的高2字节和低2字节中。
mode_bits 应为 0x0000(32位模式),0x0100(16位模式)或 0x0200(8位模式)。
参数:
-
int32_t a[]– [inout] 输出向量 -
const int32_t b[]– [in] 输入向量 -
const unsigned length_bytes– [in] 要输出的总字节数 -
const int32_t c– [in] 用于填充内部缓冲区的偶数索引字的值 -
const int32_t d– [in] 用于填充内部缓冲区的奇数索引字的值 -
const right_shift_t b_shr– [in] 输入向量b的移位量 -
const unsigned mode_bits– [in] 模式位,用于确定位模式(32位、16位或8位)
参考性能: