32-Bit Vector API
#define VECT_SQRT_S32_MAX_DEPTH
vect_s32_sqrt()函数能够计算的最大位深度。
定义值:
31
另请参见:vect_s32_sqrt
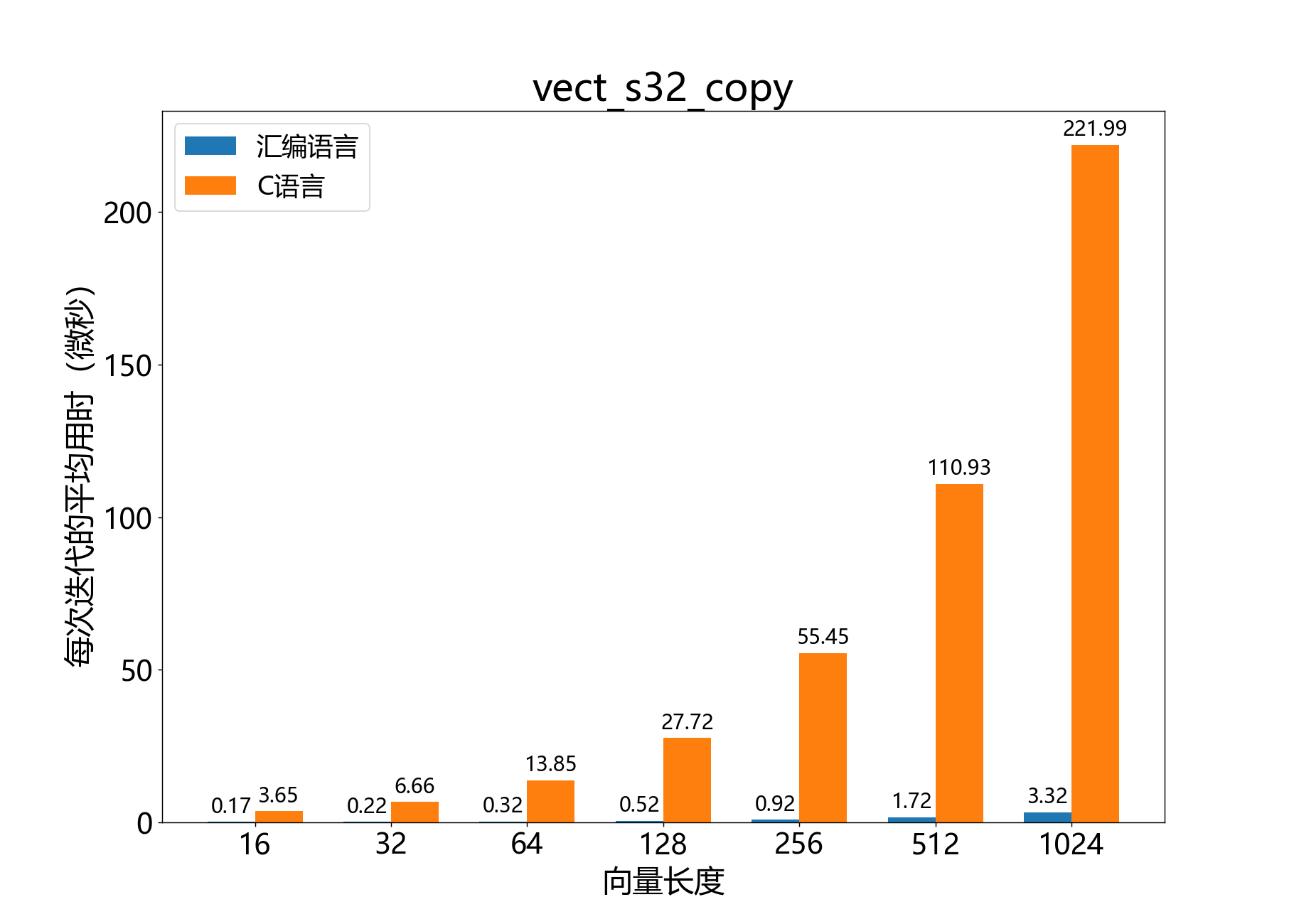
headroom_t vect_s32_copy()
将一个32位向量复制到另一个向量。
该函数实际上是memcpy的约束版本。在满足以下约束条件的情况下,该函数应比memcpy稍快。
a[]是要复制元素的输出向量。
b[]是要从中复制元素的输入向量。
a和b必须分别从字对齐的地址开始。
length是要复制的元素数量。length必须是8的倍数。
操作:
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const unsigned length– [in] 向量 和 中的元素数量
返回值: 输出向量 的头空间
异常: 如果a或b不是字对齐的,则引发ET_LOAD_STORE异常(参见 笔记:向量对齐)
参考性能:
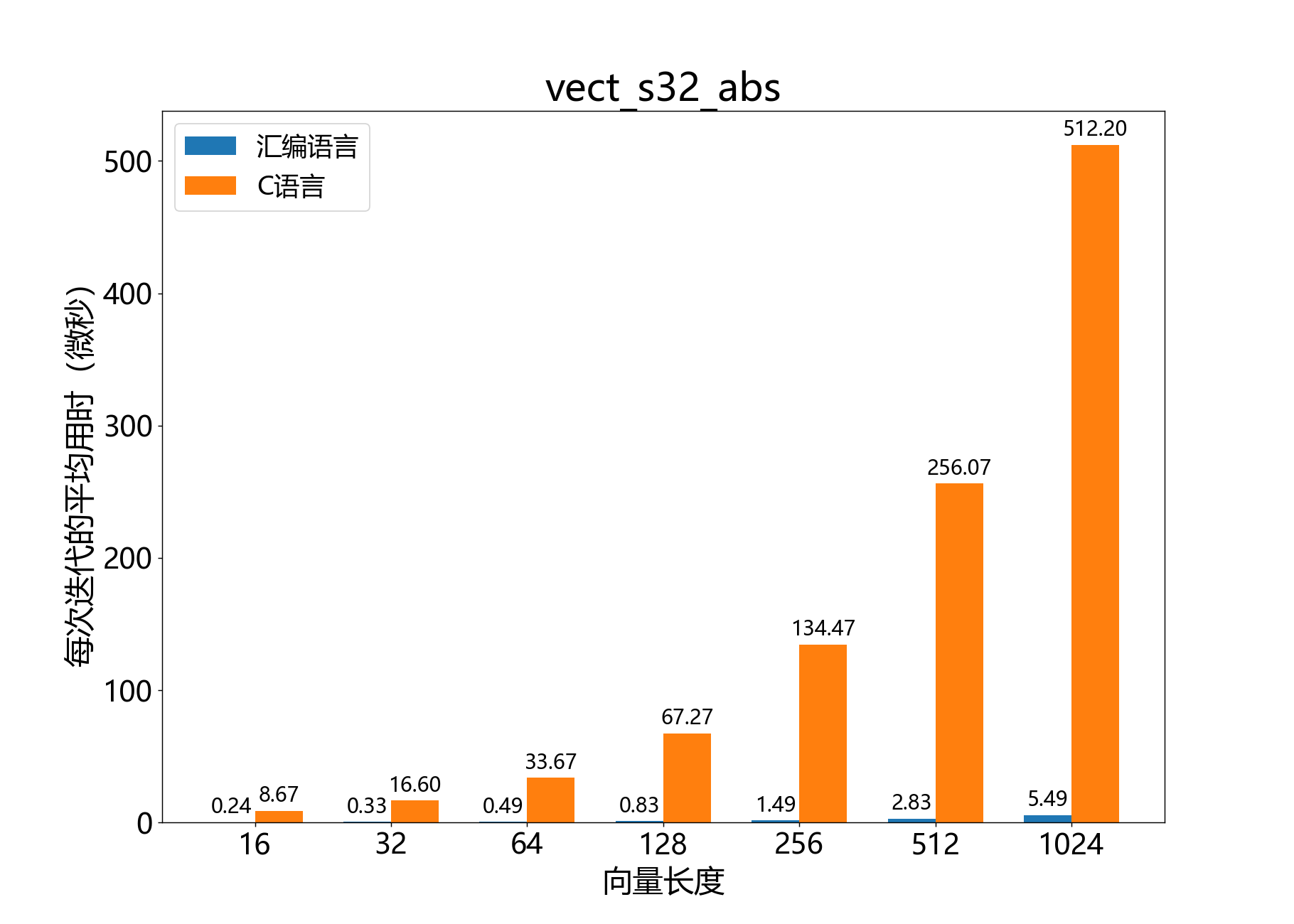
headroom_t vect_s32_abs()
计算32位向量的逐元素绝对值。
a[]和b[]分别表示32位向量 和 。每个向量必须从字对齐的地址开始。该操作可以在b[]上安全地原地执行。
length是每个向量中的元素数量。
操作:
块浮点数:
如果 是BFP向量 的尾数,则输出向量 是BFP向量 的尾数,其中 。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const unsigned length– [in] 向量 和 中的元素数量
返回值: 输出向量 的头空间。
异常: 如果a或b不是字对齐的,则引发ET_LOAD_STORE异常(参见 笔记:向量对齐)
参考性能:
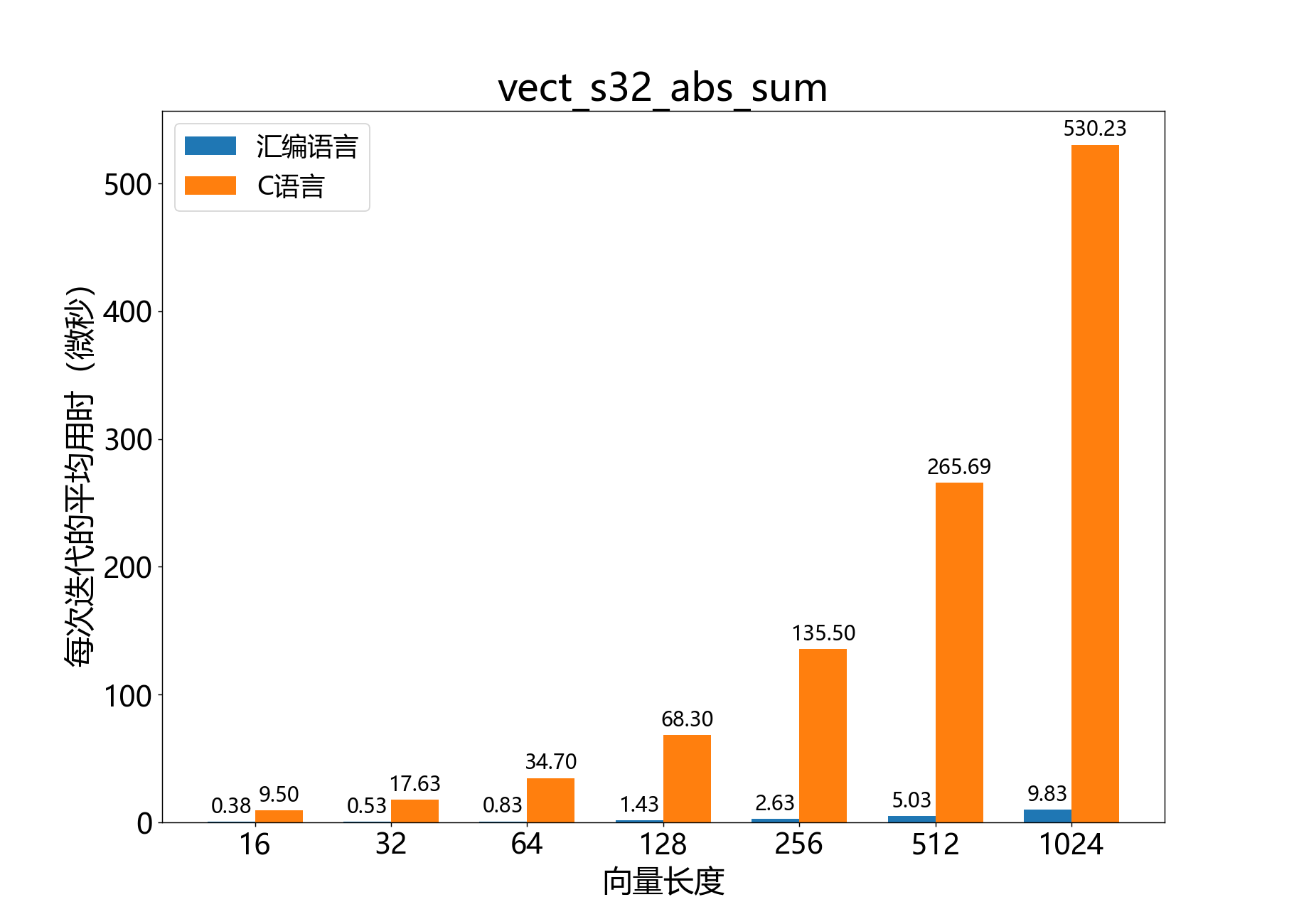
int64_t vect_s32_abs_sum()
计算32位向量元素的绝对值之和。
b[]表示32位尾数向量 。b[]必须从字对齐的地址开始。
length是 中的元素数量。
操作:
块浮点数:
如果 是BFP向量 的尾数,则返回值 是浮点数 的64位尾数,其中 。
其他详细信息:
内部上,和值累积到8个独立的40位累加器中。这些累加器使用对称的40位饱和逻辑(范围为 )来处理每个添加的元素。最后,将8个累加器相加得到64位值 ,该值由此函数返回。在这最后一步中,不应用饱和逻辑。
由于在计算绝对值时应用了对称的32位饱和逻辑,在每个元素都是INT32_MIN的极端情况下,每个累加器可以累积 个元素,然后才可能发生饱和。因此,具有 位头空间的情况下, 中的元素数量少于 时,不会发生中间结果的饱和。
如果 的长度大于 ,则可以将和值分段计算,在多次调用该函数时,将部分结果在用户代码中求和。
参数:
-
const int32_t b[]– [in] 输入向量 -
const unsigned length– [in] 向量 中的元素数量
返回值: 64位和值
异常: 如果b不是字对齐的,则引发ET_LOAD_STORE异常(参见 笔记:向量对齐)
参考性能:
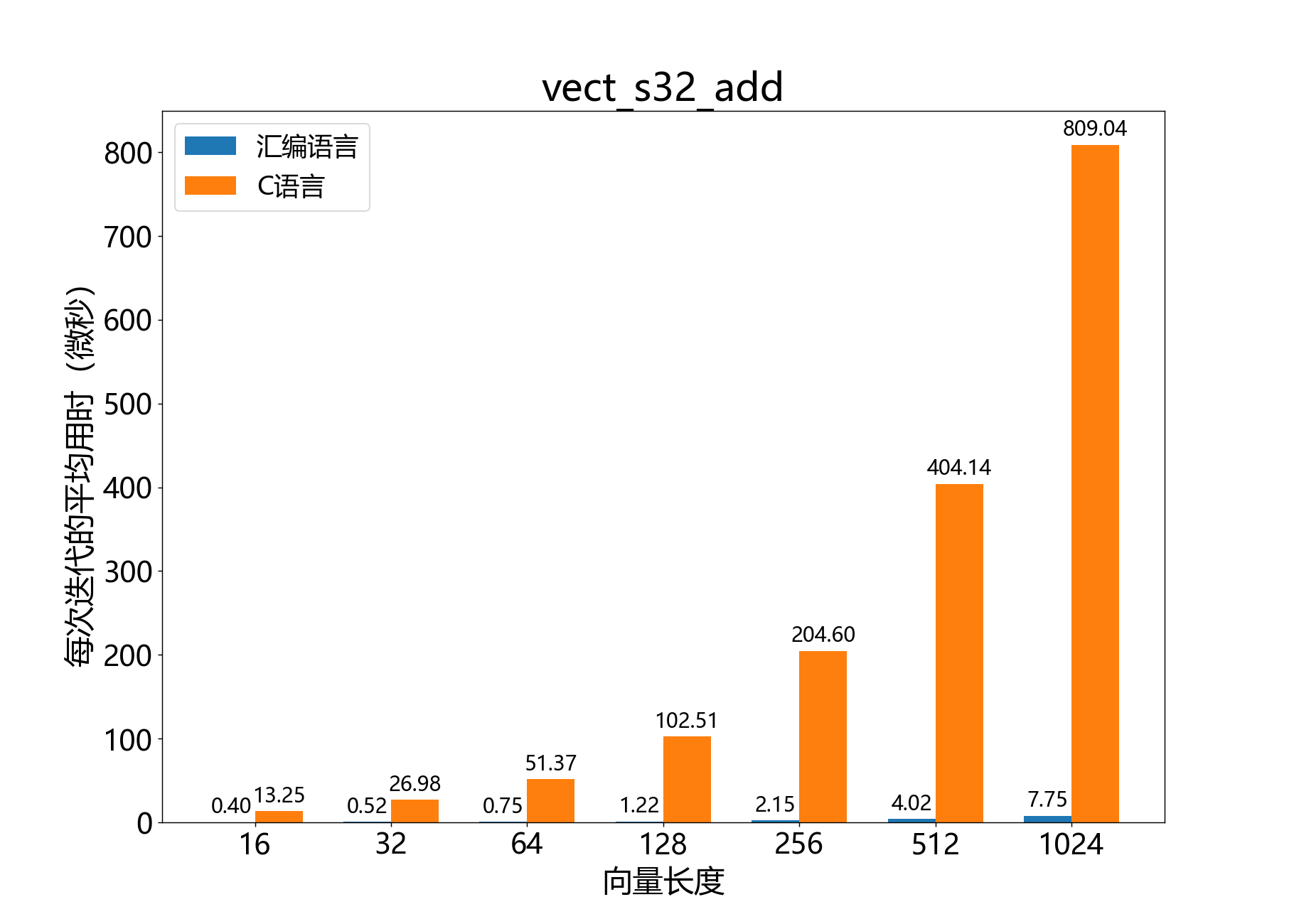
headroom_t vect_s32_add()
将两个32位向量相加。
a[]、b[]和c[]分别表示32位尾数向量 、和。每个向量必须从对齐的地址开始。此操作可以安全地原地在b[]或c[]上执行。
length是向量中的元素数。
b_shr和c_shr是应用于和的有符号算术右移。
操作:
块浮点
如果和是BFP向量和的尾数,则结果向量是BFP向量的尾数。
在这种情况下,必须选择和,使得。只有当尾数与相同的指数相关联时,才有意义地相加或相减尾数。
函数vect_s32_add_prepare()可以根据输入指数和以及输入头空间和来获取、和的值。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const int32_t c[]– [in] 输入向量const unsigned length– [in] 向量、和中的元素数const right_shift_t b_shr– [in] 应用于的右移const right_shift_t c_shr– [in] 应用于的右移
返回:
输出向量的头空间。
异常:
ET_LOAD_STORE:�如果a、b或c不是字对齐的(参见笔记:向量对齐)
参见:
vect_s32_add_prepare()
参考性能:
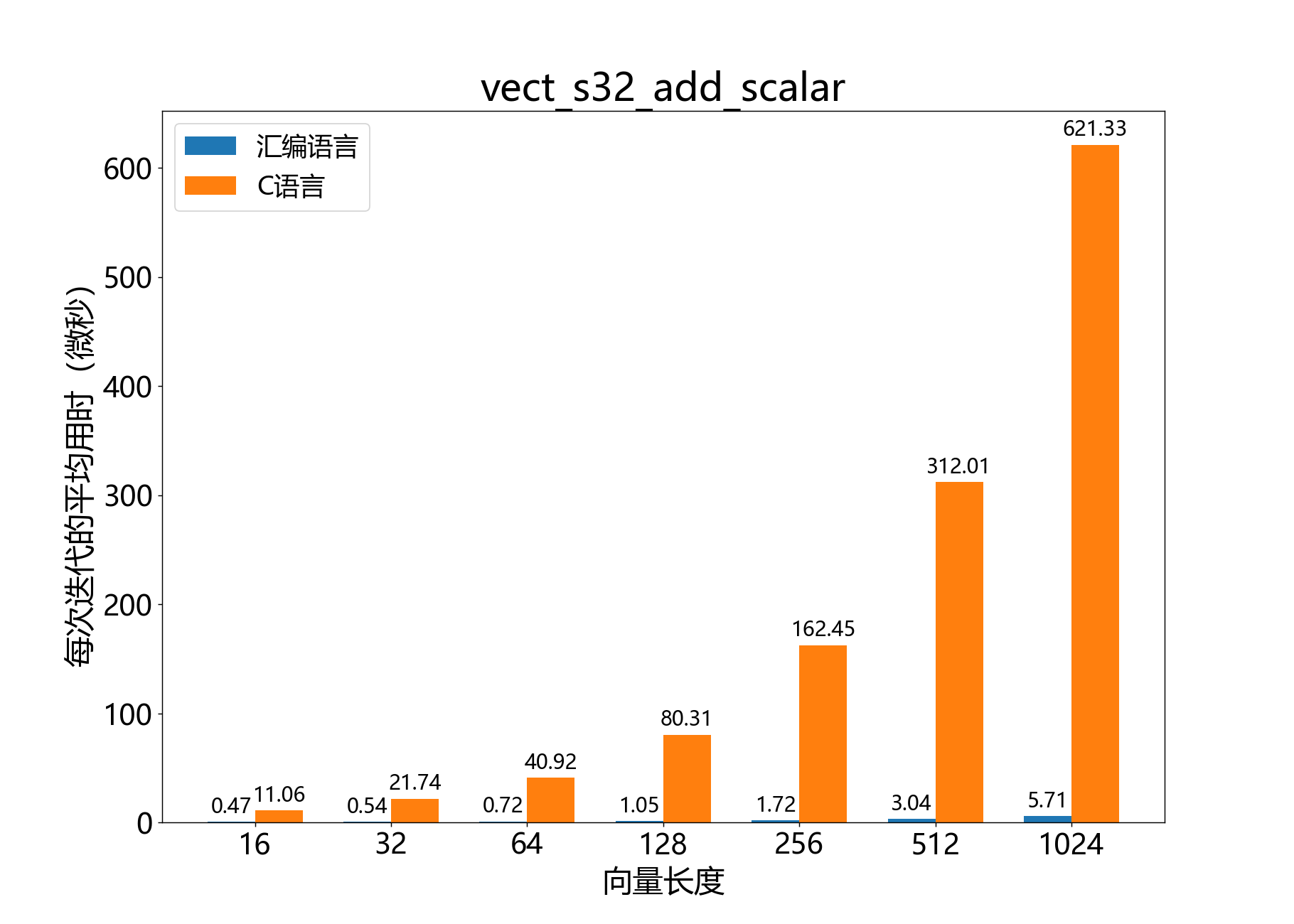
headroom_t vect_s32_add_scalar()
将标量加到32位向量中。
a[]、b[]分别表示32位尾数向量和。每个向量必须从对齐的地址开始。此操作可以安全地原地在b[]上执行。
c是要添加到的每个元素的标量。
length是向量中的元素数。
b_shr是应用于的有符号算术右移。
操作:
块浮点
如果的元素是BFP向量的尾数,是浮点值的尾数,则结果向量是BFP向量的尾数。
在这种情况下,必须选择和,使得。只有当尾数与相同的指数相关联时,才有意义地相加或相减尾数。
函数vect_s32_add_scalar_prepare()可以根据输入指数和以及输入头空间和来获取、和的值。
注意,是vect_s32_add_scalar_prepare()的输出,但不是此函数的参数。vect_s32_add_scalar_prepare()生成的由用户应用,并将结果作为输入c传递。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const int32_t c– [in] 输入标量const unsigned length– [in] 向量和中的元素数const right_shift_t b_shr– [in] 应用于的右移
返回:
输出向量的头空间。
异常:
ET_LOAD_STORE:如果a或b不是字对齐的(参见笔记:向量对齐)
参见:
vect_s32_add_scalar_prepare()
参考性能:
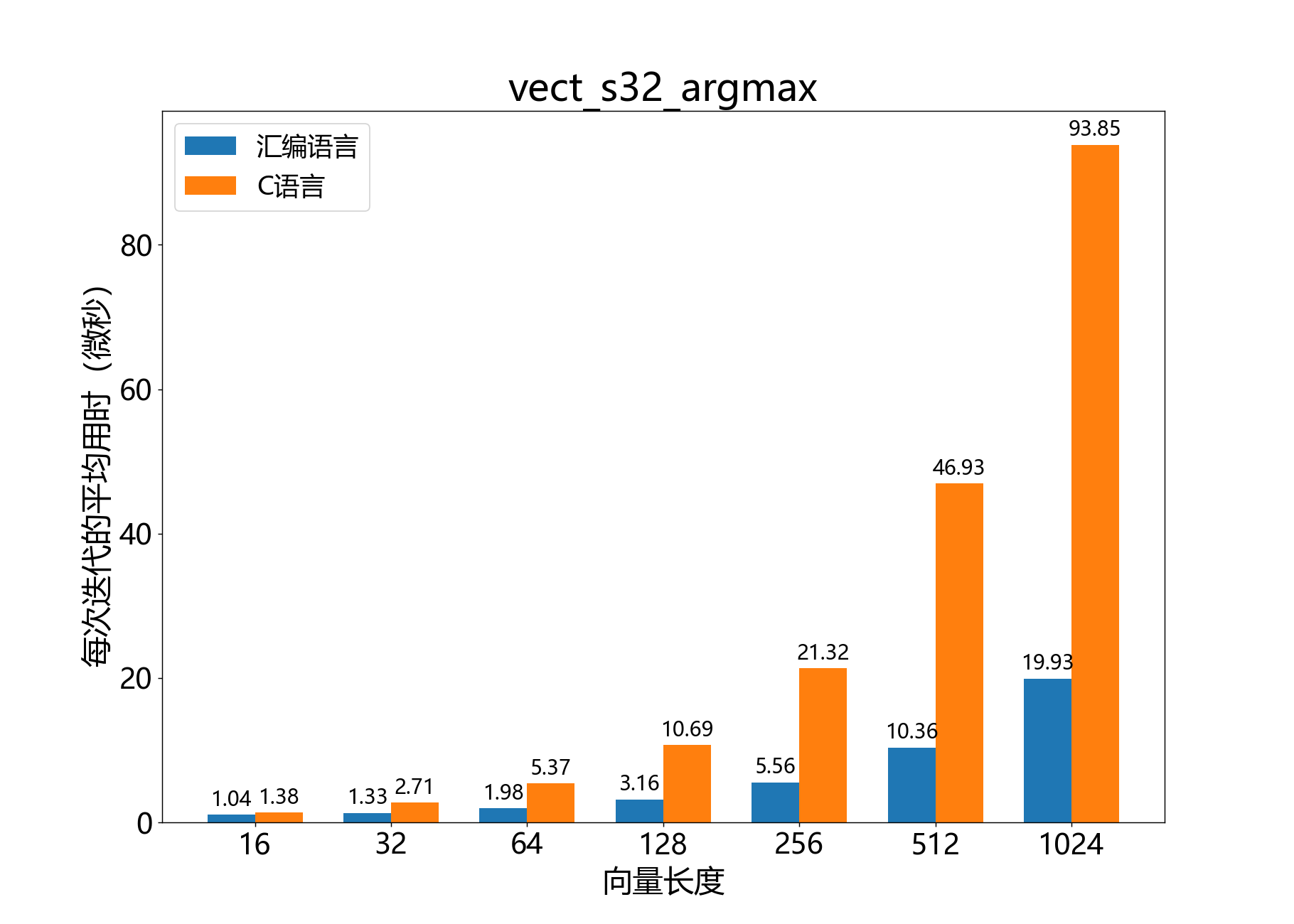
unsigned vect_s32_argmax()
获取32位向量中最大元素的数组索引。
b[]表示32位输入向量。它必须从对齐的地址开始。
length是中的元素数。
操作:
参数:
const int32_t b[]– [in] 输入向量const unsigned length– [in] 中的元素数
返回:
,向量中最大元素的索引。如果最大值有多个,返回最低索引。
异常:
ET_LOAD_STORE:如果b不是字对齐的(参见笔记:向量对齐)
参考性能:
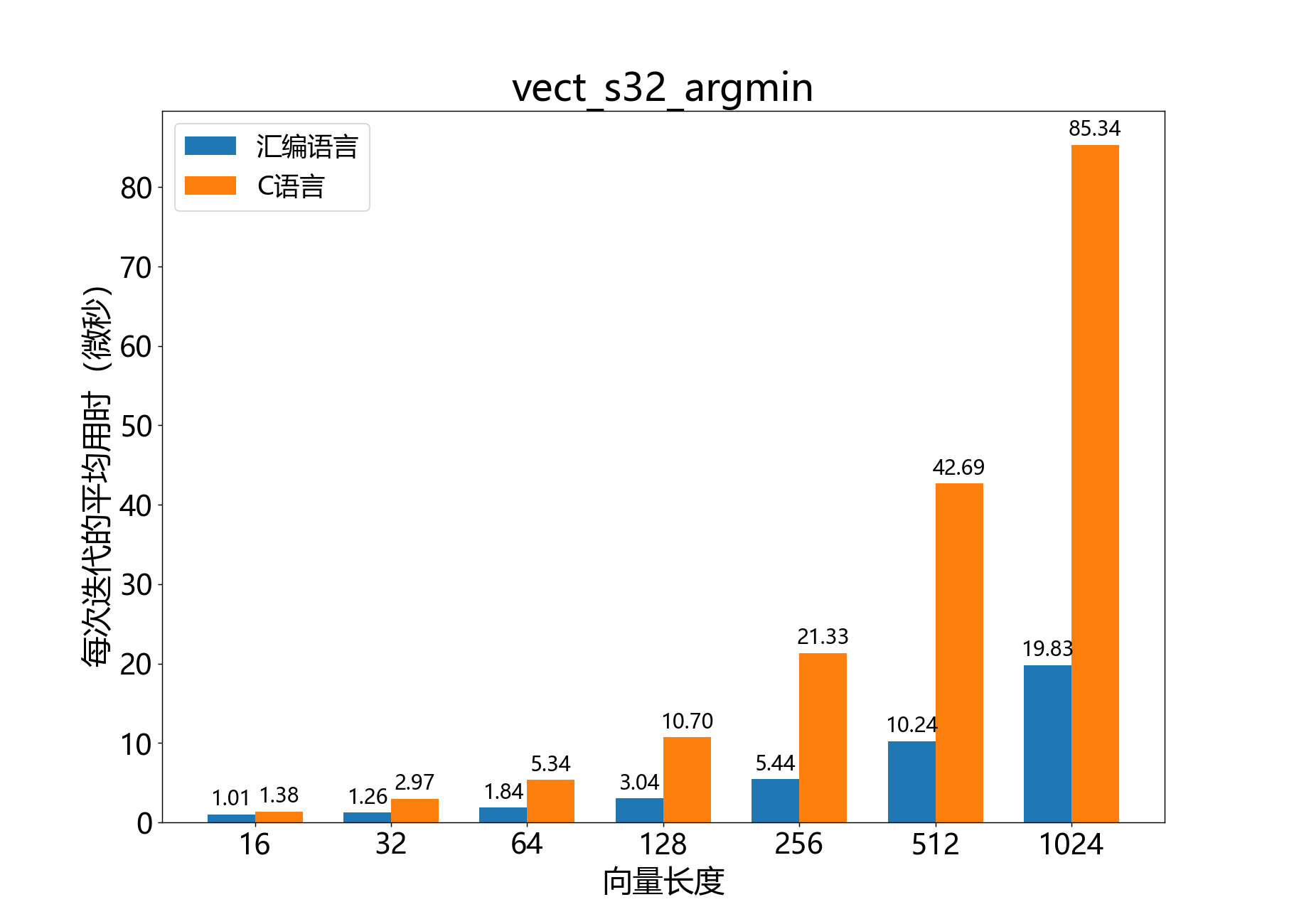
unsigned vect_s32_argmin()
获取32位向量中最小元素的数组索引。
b[]表示32位输入向量。它必须从对齐的地址开始。
length是中的元素数。
操作:
参数:
const int32_t b[]– [in] 输入向量const unsigned length– [in] 中的元素数
返回:
,向量中最小元素的索引。如果最小值有多个,返回最低索引。
异常:
ET_LOAD_STORE:如果b不是字对齐的(参见笔记:向量对齐)
参考性能:
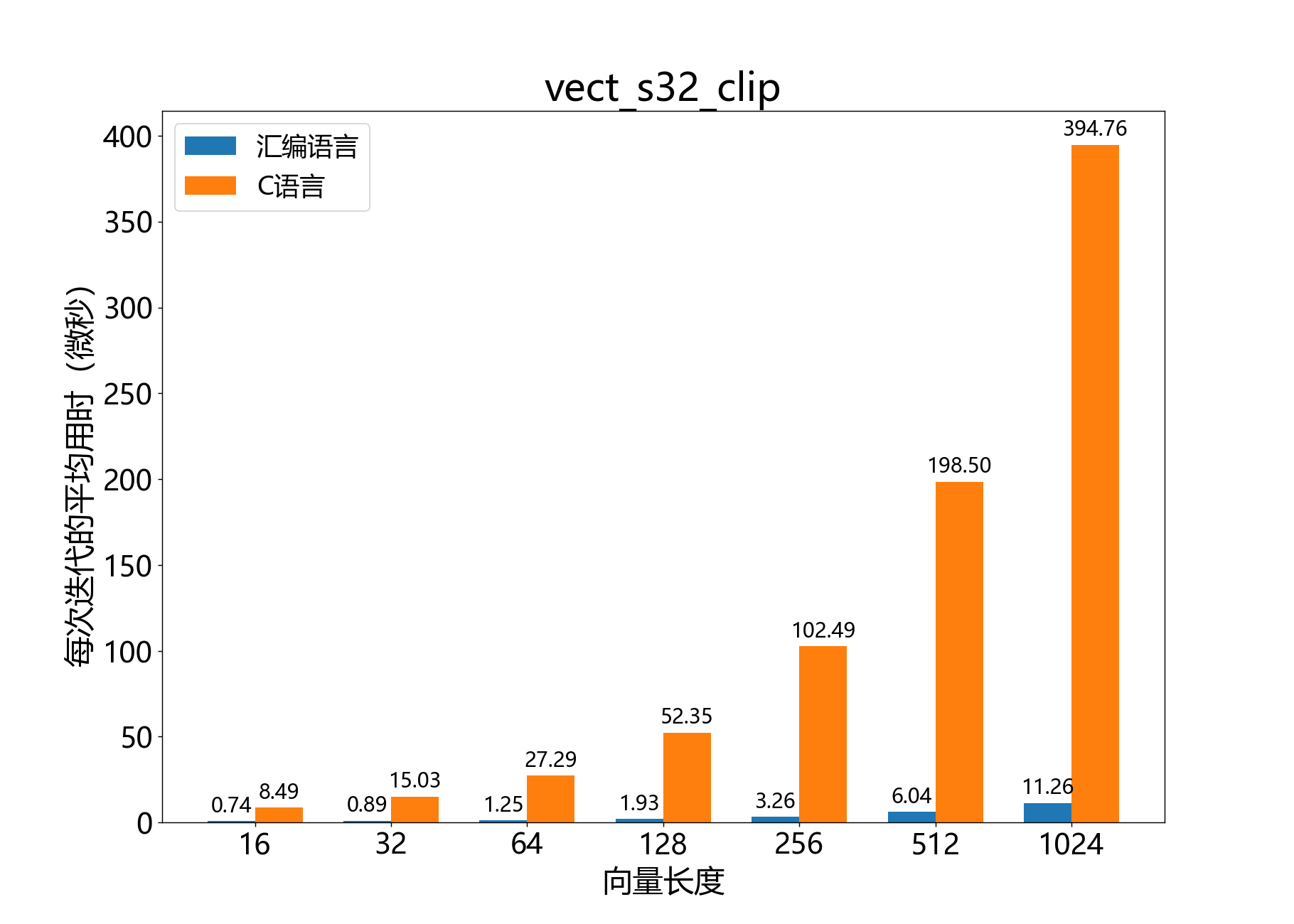
headroom_t vect_s32_clip()
将一个32位向量的元素限制在指定范围内。
a[] 和 b[] 分别表示32位向量 和 。每个向量必须从按字对齐的地址开始。此操作可以安全地就地在 b[] 上执行。
length 是向量中的元素数量。
lower_bound 和 upper_bound 分别是剪裁范围的下界和上界。这些边界在应用 b_shr 后仅对 的每个元素进行检查。
b_shr 是应用于 元素的有符号算术右移,用于与上界和下界进行比较之前。
如果 是BFP向量 的尾数,则输出BFP向量 的指数 由 给出。
操作:
块浮点数:
如果 是BFP向量 的尾数,那么输出向量 是BFP向量 的尾数,其中 。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const unsigned length– [in] 向量 和 中的元素数量const int32_t lower_bound– [in] 剪裁范围的下界const int32_t upper_bound– [in] 剪裁范围的上界const right_shift_t b_shr– [in] 应用于 元素的算术右移
返回值:
输出向量 的头空间。
异常:
如果 a 或 b 的地址不是按字对齐的,则引发 ET_LOAD_STORE 异常。
参考性能:
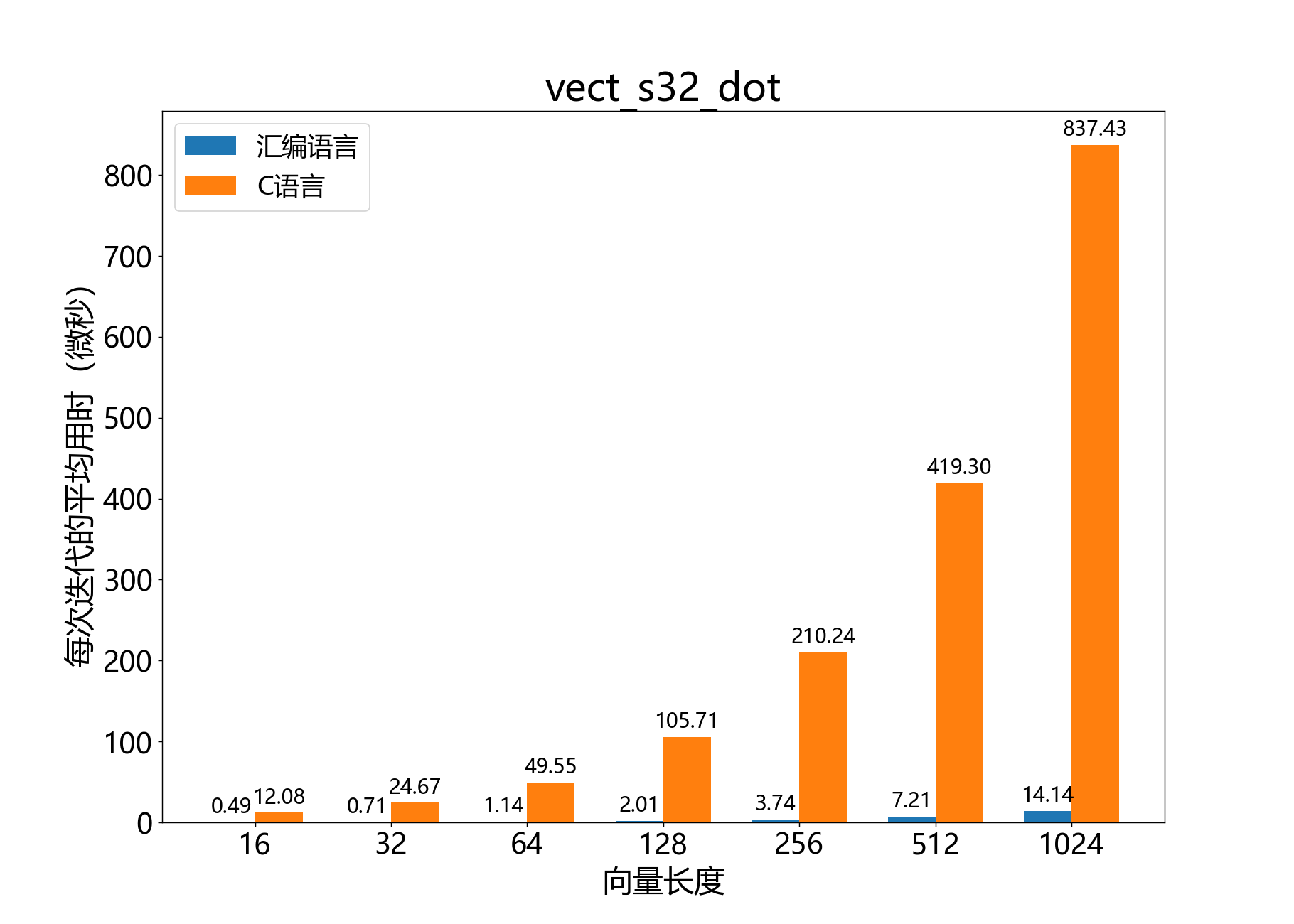
int64_t vect_s32_dot()
计算两个32位向量的内积。
b[] 和 c[] 分别表示32位尾数向量 和 。每个向量必须从按字对齐的地址开始。
length 是向量中的元素数量。
b_shr 和 c_shr 分别是应用于 和 的有符号算术右移。
操作:
块浮点数:
如果 和 是BFP向量 和 的尾数,那么结果 是结果 的64位尾数,其中 。
如果需要,可以将 的位深度缩减为32位,得到新的结果 ,其中 ,。
可以使用函数 vect_s32_dot_prepare() 根据输入的指数 和 以及输入的头空间 和 来获取 、 和 的值。
其他细节:
应用于每个64位乘积 的30位舍入右移是硬件的特性,无法避免。因此,如果输入向量 和 的头空间太大(即 ),则和可能会有效地消失。为避免这种情况,可以使用负值的 b_shr 和 c_shr(条件是 和 ,如果要避免 和 的饱和)。 和 的头空间越小,最终结果的精度就越高。
参数:
const int32_t b[]– [in] 输入向量const int32_t c[]– [in] 输入向量const unsigned length– [in] 向量 和 中的元素数量const right_shift_t b_shr– [in] 应用于 的右移const right_shift_t c_shr– [in] 应用于 的右移
返回值:
向量 和 的内积,按上述方式进行缩放。
异常:
如果 b 或 c 的地址不是按字对齐的,则引发 ET_LOAD_STORE 异常。
参考性能:
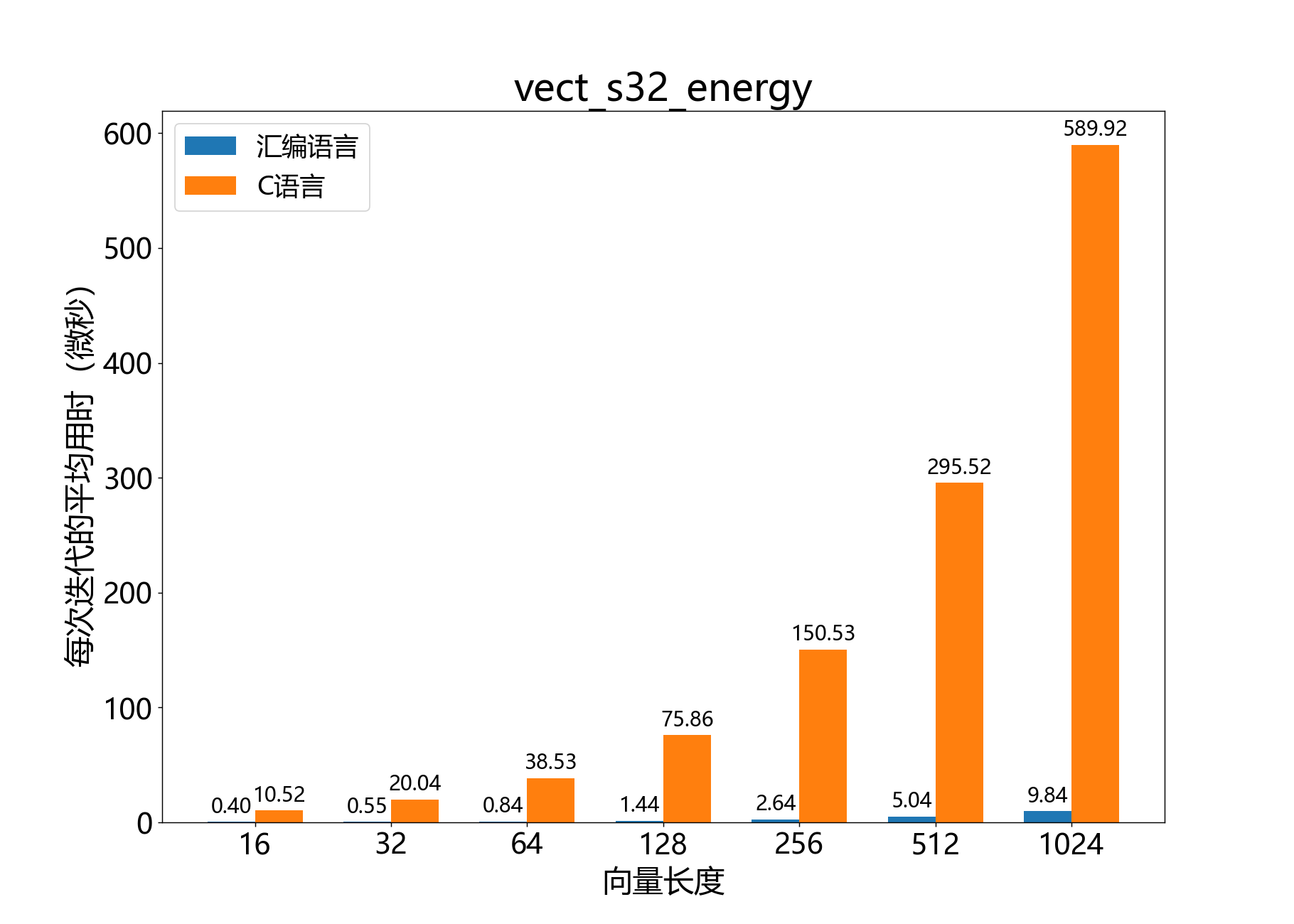
int64_t vect_s32_energy()
计算32位向量的能量(元素平方和)。
函数 vect_s32_energy 用于计算32位向量的能量。它接受向量 b[]、b[] 的元素数量(长度)以及应用于 b[] 的右移位数 b_shr 作为输入。
操作过程:
块浮点表示:
如果 b[] 是BFP向量 的尾数,则浮点结果为 ,其中64位尾数 a 由该函数返回,。
函数 vect_s32_energy_prepare() 可用于根据输入的指数 和 以及输入的头空间 和 获取 、 和 的值。
其他细节:
对于64位乘积 的每个元素应用的30位舍入右移是硬件的特性,无法避免。因此,如果输入向量 的头空间过大(即 ),则和可能会有效地消失。为了避免这种情况,可以使用负值的 b_shr(但要求 ,以避免 的饱和)。 的头空间越小,最终结果的精度就越高。
在内部,每个乘积 累积到八个40位累加器中(同时使用),并且每个添加的值都应用对称的40位饱和逻辑(边界约为 )。所采用的饱和算术不是可结合的,并且如果在中间步骤发生饱和,不会给出任何指示。为了避免饱和错误,length 不应大于 ,其中 是 的头空间。
如果调用者的尾数向量长度超过这个限制,可以通过在输入的子序列上多次调用此函数以获取部分结果,并在用户代码中将结果相加来获得完整结果。
在许多情况下,调用者可能具有先验知识,即饱和是不可能的(或非常接近),在这种情况下,可以忽略此准则。然而,这种情况是特定于应用程序的,并且远远超出了本文档的范围,因此留给用户自行决定。
参数:
-
const int32_t b[]– [in] 输入向量 -
const unsigned length– [in]b[]的元素数量 -
const right_shift_t b_shr– [in] 应用于 的右移位数
返回值:
- 向量 的64位尾数能量
异常:
- 如果
b的对齐方式不是字对齐,则引发 ET_LOAD_STORE(参见 笔记:向量对齐)
参�考性能:
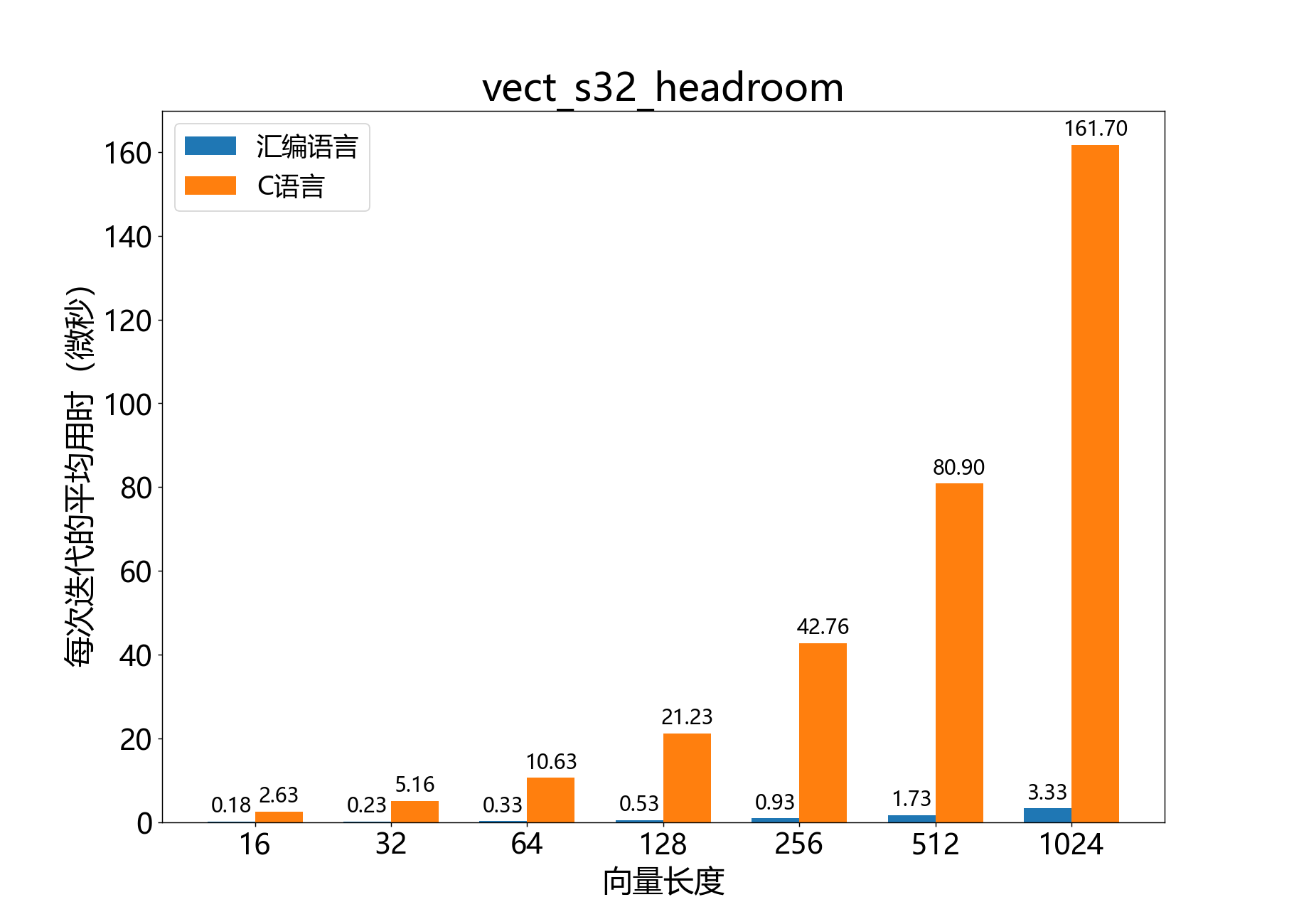
headroom_t vect_s32_headroom()
计算32位向量的头空间。
函数 vect_s32_headroom 用于计算32位向量的头空间。它接受向量 x[] 和 x[] 的元素数量(长度)作为输入。
N位整数的头空间是整数值左移而不丢失任何信息的位数。等价地,它比前导符号位的数量少1。
int32_t 数组的头空间是其每个 int32_t 元素的头空间的最小值。
该函数高效地遍历 a[] 的元素以确定其头空间。
操作过程:
参数:
-
const int32_t x[]– [in] 输入向量 -
const unsigned length– [in]x[]的元素数量
返回值:
- 向量 的头空间
异常:
- 如果
x的对齐方式不是字对齐,则引发 ET_LOAD_STORE(参见 笔记:向量对齐)
另请参阅:
vect_s16_headroomvect_complex_s16_headroomvect_complex_s32_headroom
参考性能:
vect_s32_inverse()
计算32位向量元素的倒数。
该函数计算输入向量 b[] 中每个元素的倒数,并将结果存储在输出向量 a[] 中。a[] 和 b[] 必须以字对齐的地址开始。该操作可以安全地在 b[] 上原地执行。
length 参数是向量中的元素数量。
scale 参数是用于最大化结果精度的缩放因子。
执行的操作为:
如果 b[] 是BFP向量 的尾数,则结果向量 a[] 是BFP向量 的尾数,其中 。
函数 vect_s32_inverse_prepare() 可用于获取 和 scale 的值。
参数:
-
int32_t a[]– [out] 输出向量a[] -
const int32_t b[]– [in] 输入向量b[] -
const unsigned length– [in] 向量a[]和b[]的元素数量 -
const unsigned scale– [in] 计算倒数时应用的缩放因子
返回值:
headroom_t– 输出向量a[]的头空间
异常:
ET_LOAD_STORE– 如果a或b不是字对齐的,则引发异常
vect_s32_max()
找到32位向量中的最大值。
该函数在输入向量 b[] 中找到最大值,b[] 必须以字对齐的地址开始。
length 参数是 b[] 中的元素数量。
执行的操作为:
如果 b[] 是BFP向量 的尾数,则返回的值 a 是浮点值 的32位尾数,其中 。
参数:
-
const int32_t b[]– [in] 输入向量b[] -
const unsigned length– [in]b[]中的元素数量
返回值:
int32_t–b[]中的最大值
异常:
ET_LOAD_STORE– 如果b不是字对齐的,则引发�异常
vect_s32_max_elementwise()
获取两个32位向量的逐元素最大值。
该函数计算输入向量 b[] 和 c[] 的逐元素最大值,并将结果存储在输出向量 a[] 中。三个向量都必须以字对齐的地址开始。该操作可以安全地在 b[] 上原地执行,但不能在 c[] 上原地执行。
length 参数是向量中的元素数量。
b_shr 和 c_shr 参数是应用于 b[] 和 c[] 的有符号算术右移。
执行的操作为:
对于
如果 b[] 和 c[] 是BFP向量 和 的尾数,则结果向量 a[] 是BFP向量 的尾数,其中 。
函数 vect_2vec_prepare() 可用于根据输入指数 和 以及输入头空间 和 获取 、 和 的值。
参数:
-
int32_t a[]– [out] 输出向量a[] -
const int32_t b[]– [in] 输入向量b[] -
const int32_t c[]– [in] 输入向量c[] -
const unsigned length– [in] 向量a[]、b[]和c[]的元��素数量 -
const right_shift_t b_shr– [in] 应用于b[]的右移量 -
const right_shift_t c_shr– [in] 应用于c[]的右移量
返回值:
headroom_t– 向量a[]的头空间
异常:
ET_LOAD_STORE– 如果a、b或c不是字对齐的,则引发异常
vect_s32_min()
找到32位向量中的最小值。
该函数在输入向量 b[] 中找到最小值,b[] 必须以字对齐的地址开始。
length 参数是 b[] 中的元素数量。
执行的操作为:
如果 b[] 是BFP向量 的尾数,则返回的值 a 是浮点值 的32位尾数,其中 。
参数:
-
const int32_t b[]– [in] 输入向量b[] -
const unsigned length– [in]b[]中的元素数量
返回值:
int32_t–b[]中的最小值
异常:
ET_LOAD_STORE– 如果b不是字对齐的,则引发异常
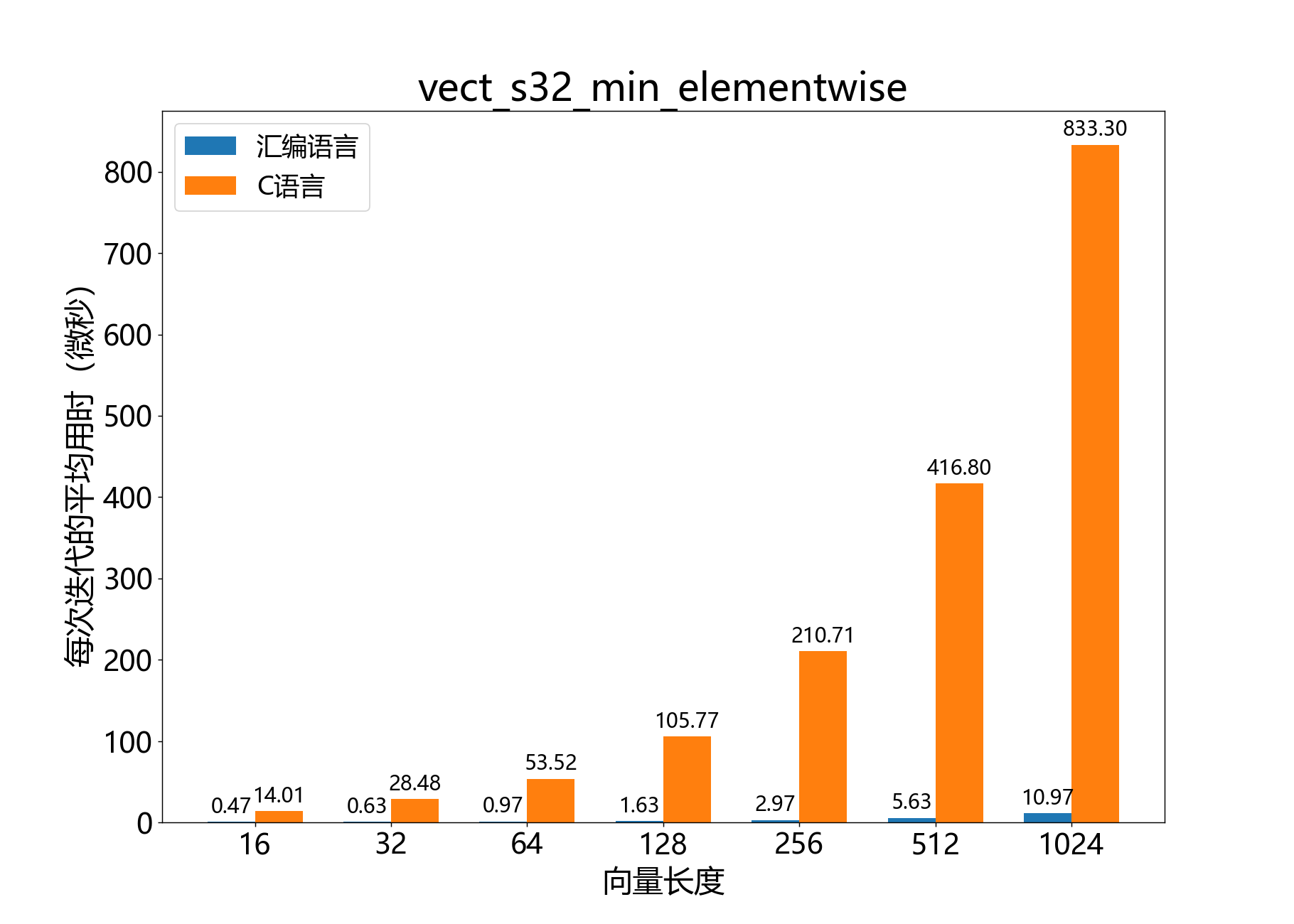
headroom_t vect_s32_min_elementwise()
获取两个32位向量的逐元素最小值。
a[]、b[]和c[]分别表示32位尾数向量、和。每个向�量必须以字对齐的地址开始。此操作可以安全地在b[]上原地执行,但不能在c[]上原地执行。
length是向量中的元素数量。
b_shr和c_shr是应用于和的有符号算术右移。
操作:
块浮点数(Block Floating-Point):
如果和是BFP向量和的尾数,则结果向量是BFP向量的尾数,其中。
函数vect_2vec_prepare()可以根据输入指数和以及输入头空间和来获取、和的值。
警告:
为了正确运行,此函数要求在应用移位后,每个尾数向量至少有1个头空间。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const int32_t c[]– [in] 输入向量const unsigned length– [in] 向量、和中的元素数量const right_shift_t b_shr– [in] 应用于的右移量const right_shift_t c_shr– [in] 应用于的右移量
返回值:
向量的头空间
异常:
如果a、b或c的地址未对齐,则引发ET_LOAD_STORE异常。
参考性能:
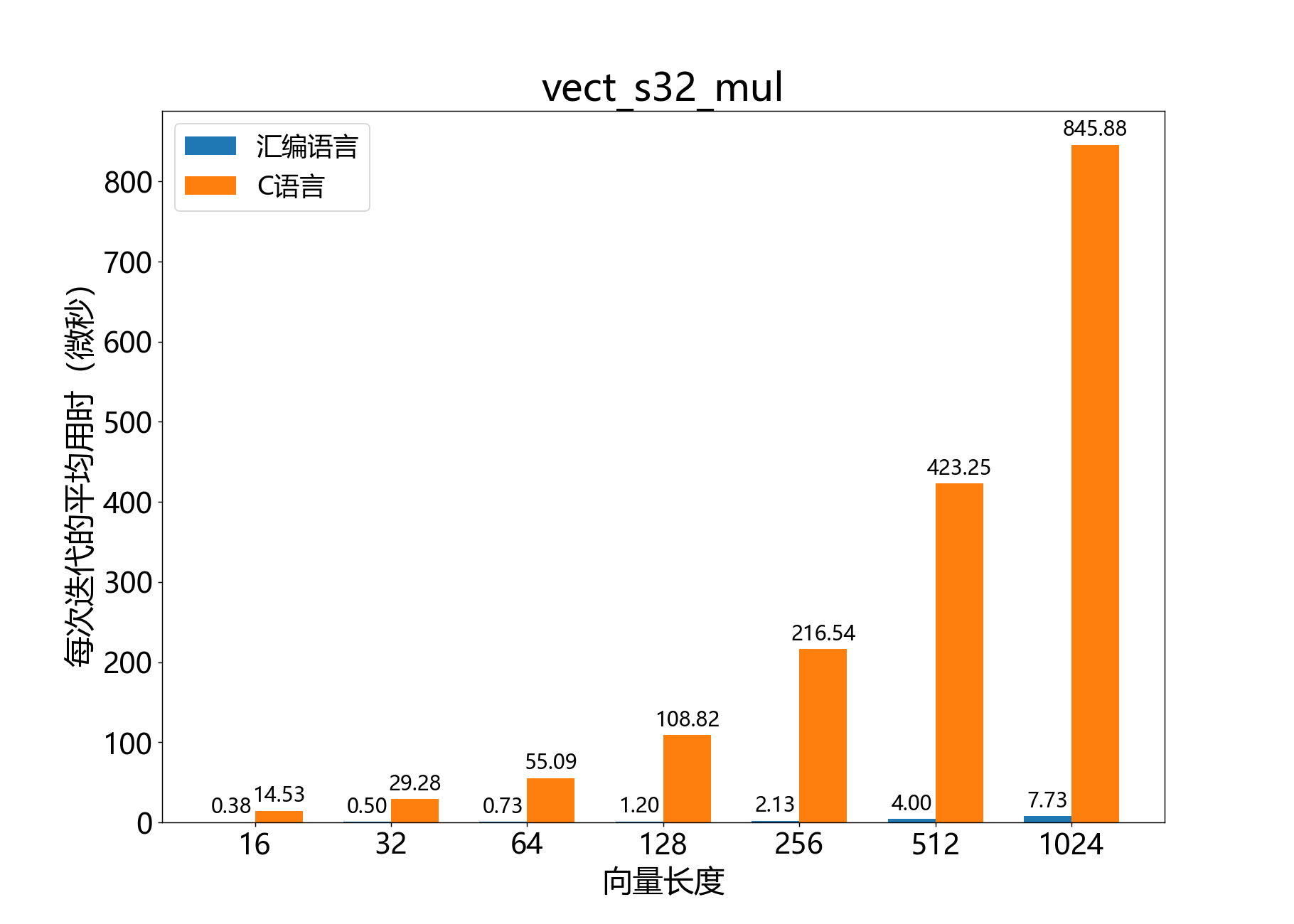
headroom_t vect_s32_mul()
逐元素将一个32位向量与另一个向量相乘。
a[]、b[]和c[]分别表示32位尾数向量、和。每个向量必须以字对齐的地址开始。此操作可以安全地在b[]或c[]上原地执行。
length是向量中的元素数量。
b_shr和c_shr是应用于和的有符号算术右移。
操作:
块浮点数(Block Floating-Point):
如果和是BFP向量和的尾数,则结果向量是BFP向量的尾数,其中。
函数vect_s32_mul_prepare()可以根据输入指数和以及输入头空间和来获取、和的值。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const int32_t c[]– [in] 输入向量const unsigned length– [in] 向量、和中的元素数量const right_shift_t b_shr– [in] 应用于的右移量const right_shift_t c_shr– [in] 应用于的右移量
返回值:
向量的头空间
异常:
如果a、b或c的地址未对齐,则引发ET_LOAD_STORE异常。
参考性能:
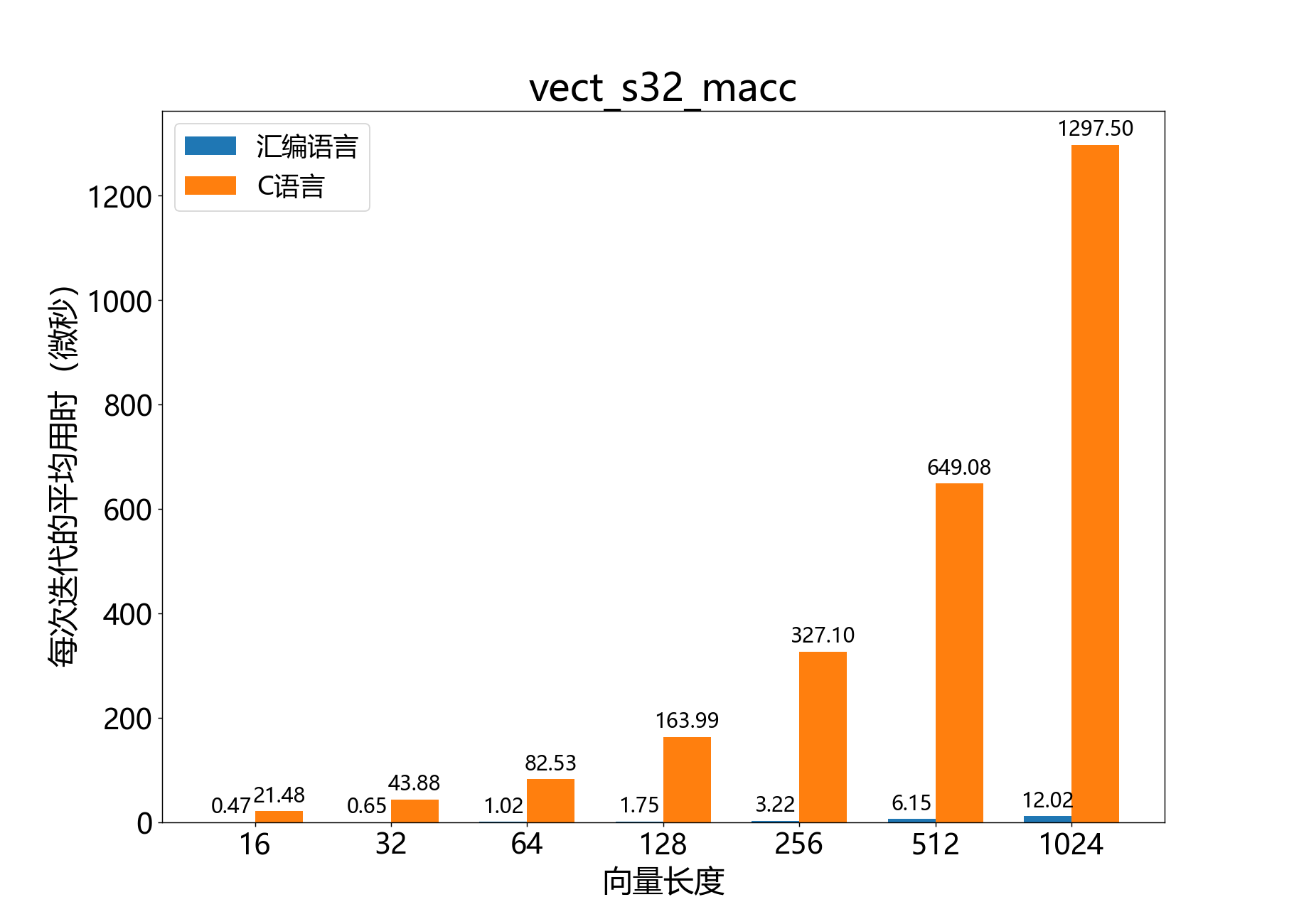
headroom_t vect_s32_macc()
逐元素将一个32位向量与另一个相乘,并将结果累加到累加器中。
acc[] 表示32位累加器尾数向量 。��每个 对应 acc[k]。
b[] 和 c[] 表示32位输入尾数向量 和 ,其中每个 对应 b[k],每个 对应 c[k]。
输入向量的每个元素必须从字对齐地址开始。
length 是向量 、 和 中的元素数量。
acc_shr、b_shr 和 c_shr 是应用于输入元素 、 和 的有符号算术右移。
操作:
块浮点数:
如果输入 和 是BFP向量 和 的尾数,输入 是累加器BFP向量 ,那么 的输出值具有指数 。
为了使累加在数学上有意义,必须选择 使得 。
函数 vect_complex_s16_macc_prepare() 可以根据输入指数 、 和 以及输入头空间 、 和 来获取 、 和 的值。
参数:
-
int32_t acc[]– [inout] 累加器 -
const int32_t b[]– [in] 输入向量 -
const int32_t c[]– [in] 输入向量 -
const unsigned length– [in] 向量 、 和 中的元素数量 -
const right_shift_t acc_shr– [in] 应用于累加器元素的有符号算术右移 -
const right_shift_t b_shr– [in] 应用于 元素的有符号算术右移 -
const right_shift_t c_shr– [in] 应用于 元素的有符号算术右移
返回值:
- 输出向量 的头空间
异常:
- ET_LOAD_STORE 如果
acc、b或c不是字对齐的(参见 笔记:向量对齐)
参见:
- vect_s32_macc_prepare
参考性能:
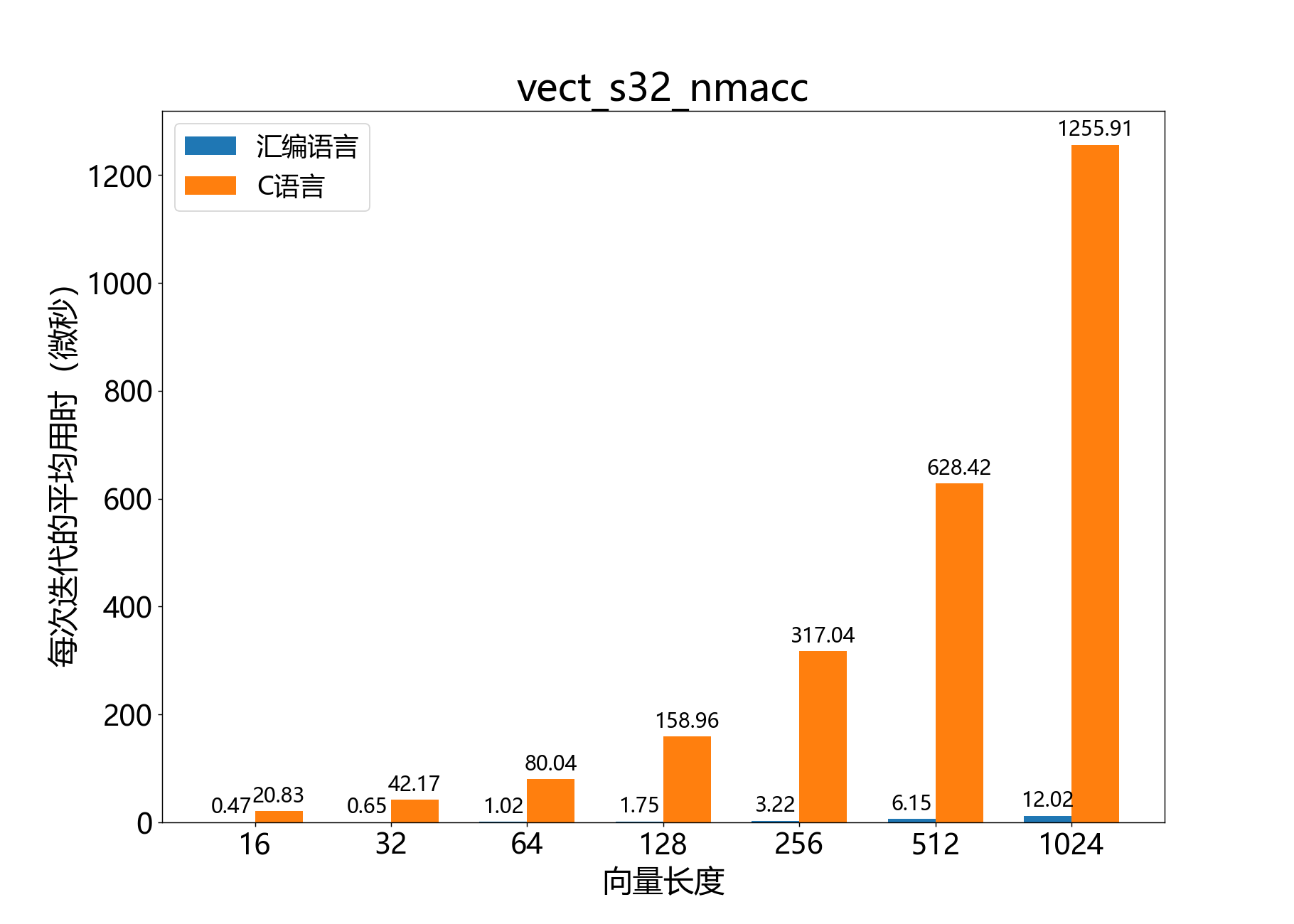
headroom_t vect_s32_nmacc()
逐元素将一个32位向量与另一个相乘,并从累加器中减去结果。
acc[] 表示32位累加器尾数向量 。每个 对应 acc[k]。
b[] 和 c[] 表示32位输入尾数向量 和 ,其中每个 对应 b[k],每个 对应 c[k]。
输入向量的每个元素必须从字对齐地址开始。
length 是向量 、 和 中的元素数量。
acc_shr、b_shr 和 c_shr 是应用于输入元素 、 和 的有符号算术右移。
操作:
块浮点数:
如果输入 和 是BFP向量 和 的尾数,输入 是累加器BFP向量 ,那么 的输出值具有指数 。
为了使累加在数学上有意义,必须选择 使得 。
函数 vect_complex_s16_macc_prepare() 可以根据输入指数 、 和 以及输入头空间 、 和 来获取 、 和 的值。
参数:
-
int32_t acc[]– [inout] 累加器 -
const int32_t b[]– [in] 输入向量 -
const int32_t c[]– [in] 输入向量 -
const unsigned length– [in] 向量 、 和 中的元素数量 -
const right_shift_t acc_shr– [in] 应用于累加器元素的有符号算术右移 -
const right_shift_t b_shr– [in] 应用于 元素的有符号算术右移 -
const right_shift_t c_shr– [in] 应用于 元素的有符号算术右移
返回值:
- 输出向量 的头空间
异常:
- ET_LOAD_STORE 如果
acc、b或c不是字对齐的(参见 笔记:向量对齐)
参见:
- vect_s32_nmacc_prepare
参考性能:
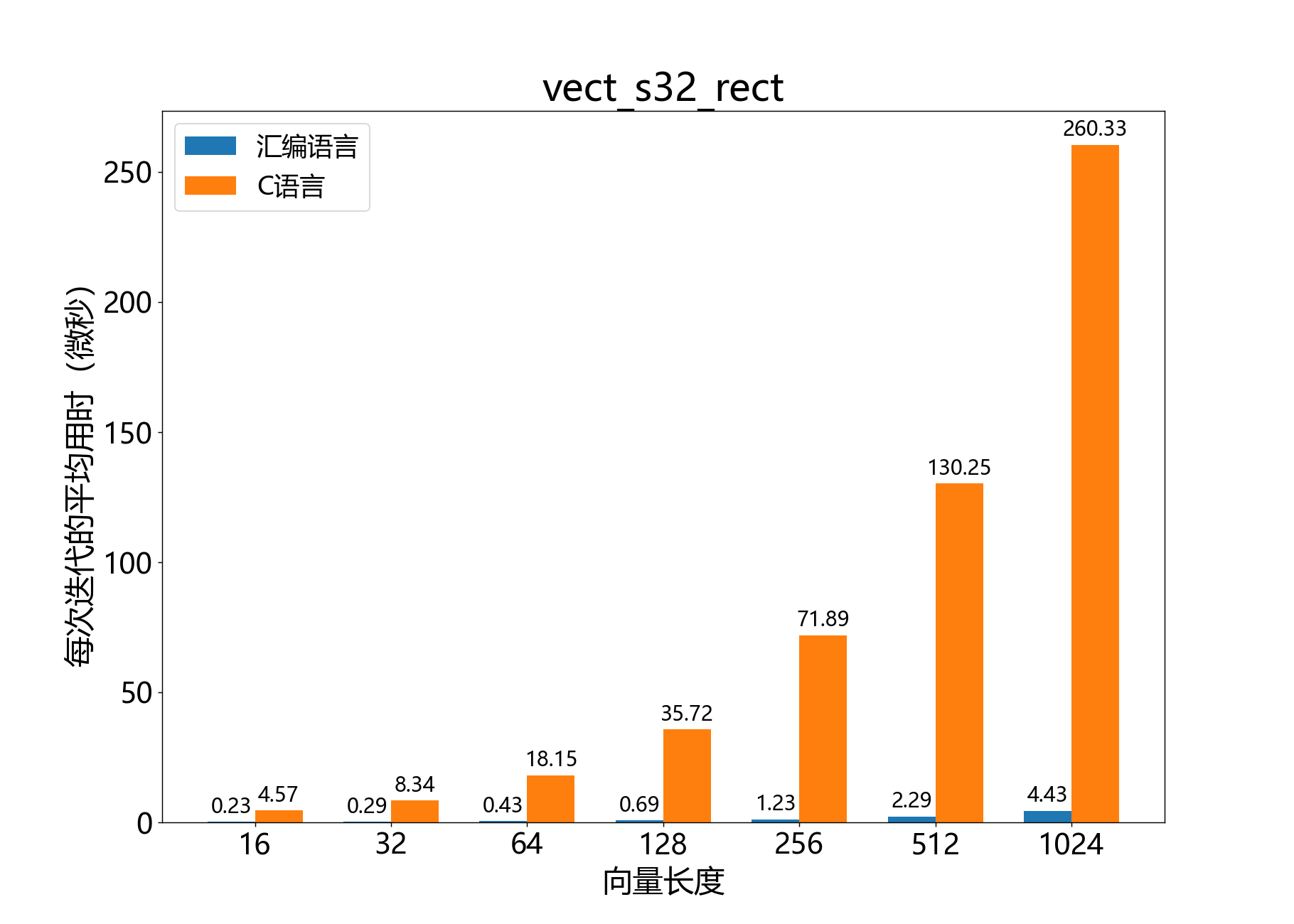
headroom_t vect_s32_rect()
对一个32位向量进行整流操作。
a[] 和 b[] 分别表示32位尾数向量 和 。每个向量必须从对齐的地址开始。这个操作可以安全地在 b[] 上原地进行。
length 是向量中的元素数量。
操作:
块浮点:
如果 是BFP向量 的尾数,则输出向量 是BFP向量 的尾数,其中 。
参数:
-
int32_t a[]– [out] 输出向量 -
const int32_t b[]– [in] 输入向量 -
const unsigned length– [in] 向量 和 的元素数量
返回值:
- 输出向量 的头空间(headroom)
异常:
ET_LOAD_STORE如果a或b的地址没有对齐(参见 笔记:向量对齐)
参考性能:
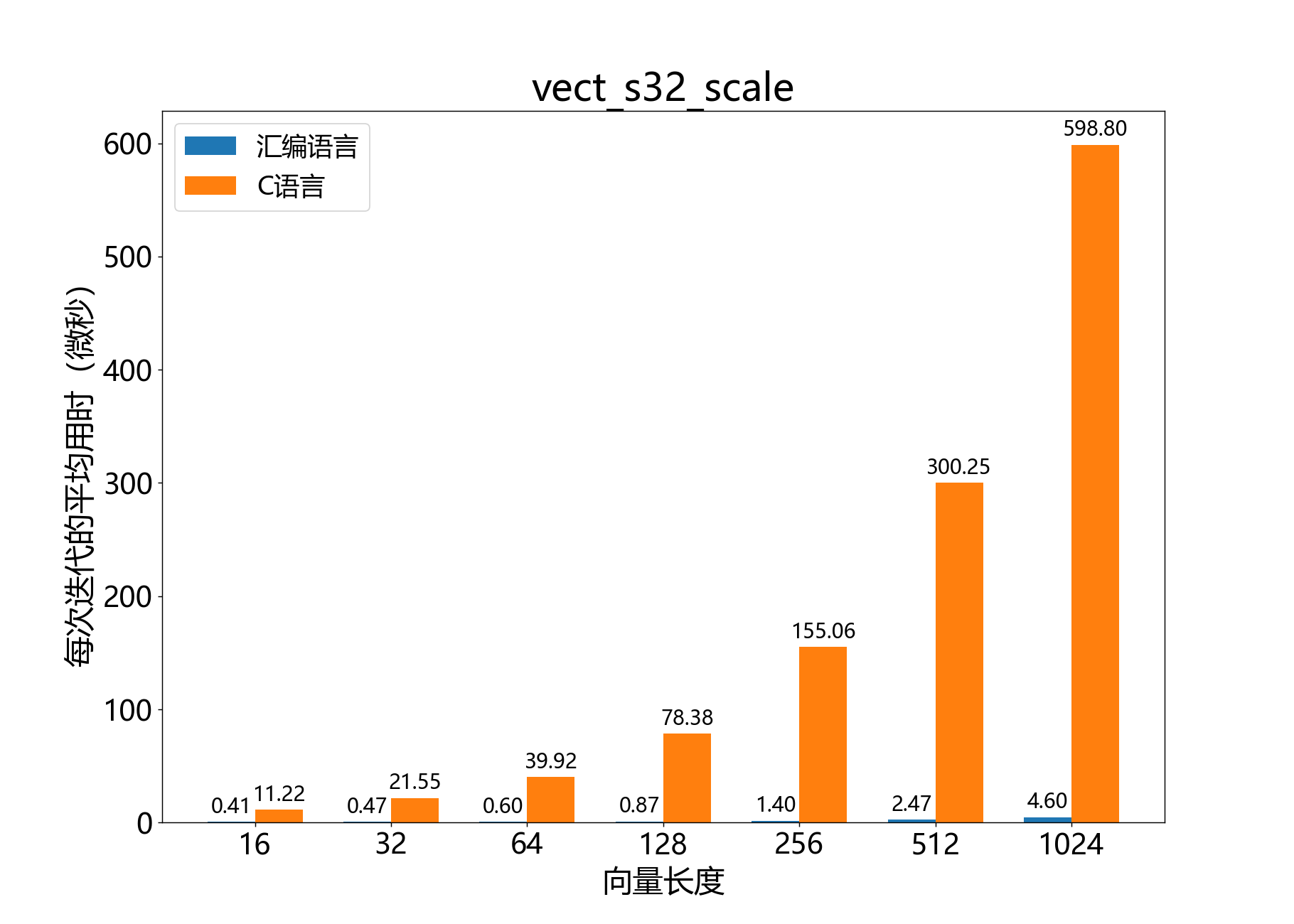
headroom_t vect_s32_scale()
将一个32位向量乘以一个标量。
a[] 和 b[] 分别表示32位尾数向量 和 。每个向量必须从对齐的地址开始。这个操作可以安全地在 b[] 上原地进行。
length 是向量中的元素数量。
c 是标量 ,用于将 的每个元素乘以。
b_shr 和 c_shr 是应用于 的每个元素和 的带符号算术右移。
操作:
块浮点:
如果 是BFP向量 的尾数, 是浮点值 的尾数,那么结果向量 是BFP向量 的尾数,其中 。
函数 vect_s32_scale_prepare() 可以根据输入的指数 和 以及输入的头空间 和 来获取 、 和 的值。
参数:
-
int32_t a[]– [out] 输出向量 -
const int32_t b[]– [in] 输入向量 -
const unsigned length– [in] 向量 和 的元素数量 -
const int32_t c– [in] 用于乘以 的元素的标量 -
const right_shift_t b_shr– [in] 应用于 的右移量 -
const right_shift_t c_shr– [in] 应用于 的右移量
返回值:
- 输出向量 的头空间(headroom)
异常:
ET_LOAD_STORE如果a或b的地址没有对齐(参见 笔记:向量对齐)
参见:
vect_s32_scale_prepare()
参考性能:
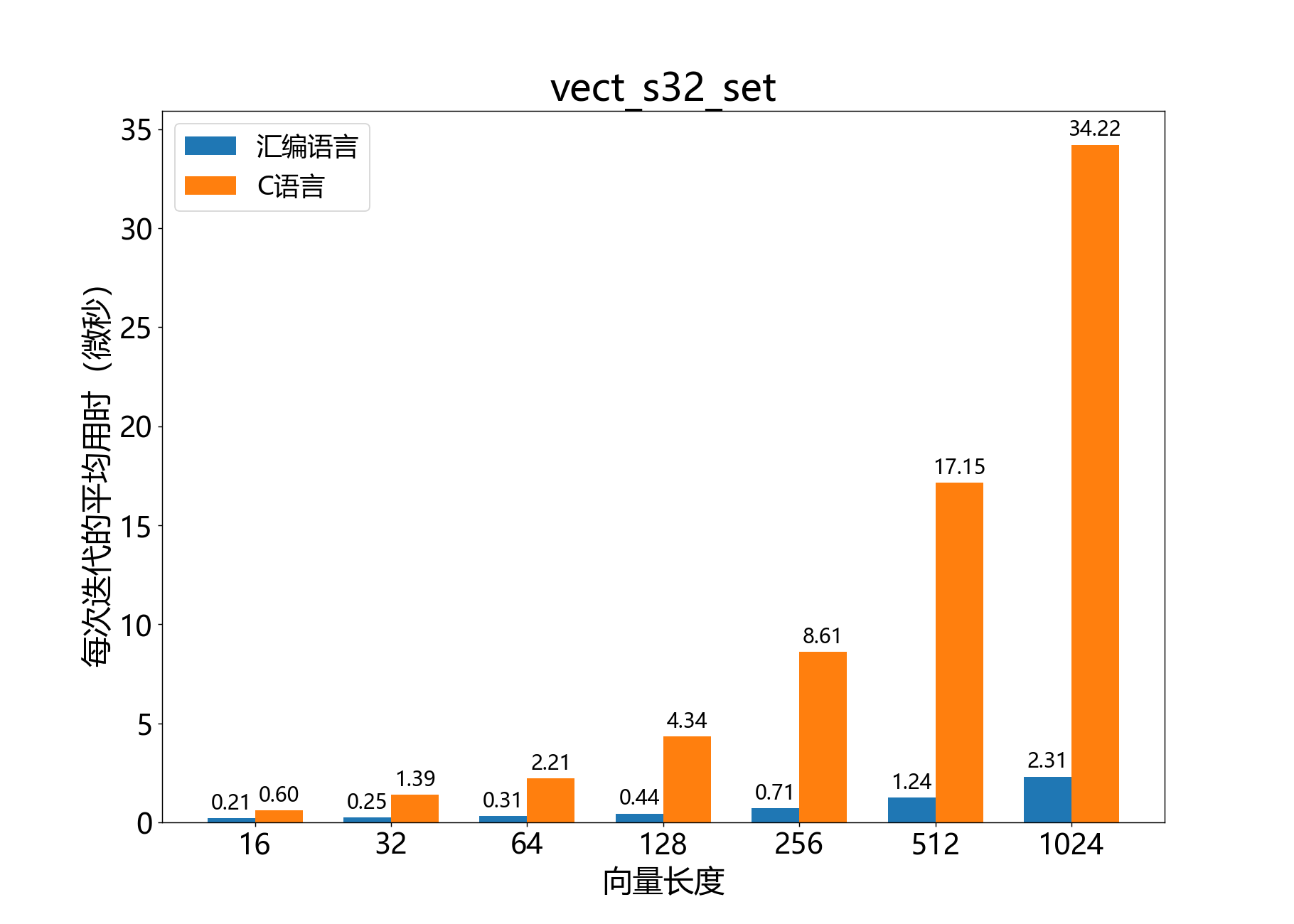
void vect_s32_set()
将32位向量的所有元素设置为指定的值。
a[] 表示32位输出向量 。a[] 必须从对齐的地址开始。
b 是要将 的每个元素设置为的新值。
操作:
块浮点:
如果 是浮点值 的尾数,那么输出向量 是BFP向量 的尾数,其中 。
参数:
-
int32_t a[]– [out] 输出向量 -
const int32_t b– [in] 的元素的新值 -
const unsigned length– [in] 向量 的元素数量
异常:
ET_LOAD_STORE如果a的地址没有对齐(参见 笔记:向量对齐)
参考性能:
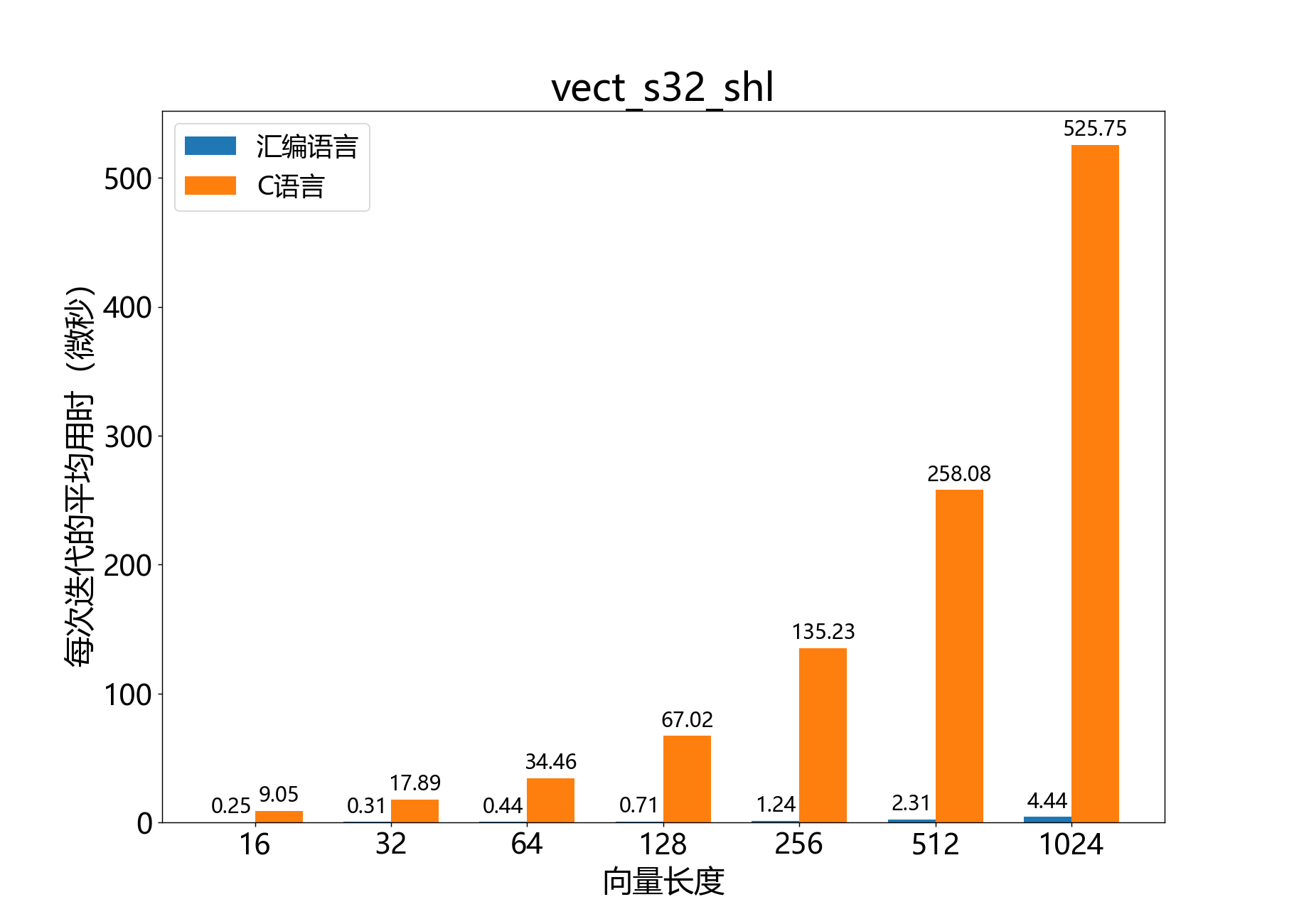
headroom_t vect_s32_shl()
将32位向量的元素左移指定的位数。
a[] 和 b[] 分别表示32位向量 和 。每个向量必须从对齐的地址开始。此操作可以在 b[] 上安全地原地执行。
length 是向量 和 中的元素数量。
b_shl 是应用于 的有符号算术左移。
操作:
块浮点数:
如果 是 BFP 向量 的尾数,则结果向量 是 BFP 向量 的尾数,其中 ,。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const unsigned length– [in] 向量 和 的元素数量const left_shift_t b_shl– [in] 应用于 元素的左移量
返回值:
输出向量 的头空间(headroom)
异常:
如果 a 或 b 的地址未对齐,则引发 ET_LOAD_STORE 异常
参考性能:
headroom_t vect_s32_shr()
将32位向量的元素右移指定的位数。
a[] 和 b[] 分别表示32位向量 和 。每个向量必须从对齐的地址开始。此操作可以在 b[] 上安全地原地执行。
length 是向量 和 中的元素数量。
b_shr 是应用于 的有符号算术右移。
操作:
块浮点数:
如果 是 BFP 向量 的尾数,则结果向量 是 BFP 向量 的尾数,其中 ,。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const unsigned length– [in] 向量 和 的元素数量const right_shift_t b_shr– [in] 应用于 元素的右移量
返回值:
输出向量 的头空间(headroom)
异常:
如果 a 或 b 的地址未对齐,则引发 ET_LOAD_STORE 异常
参考性能:
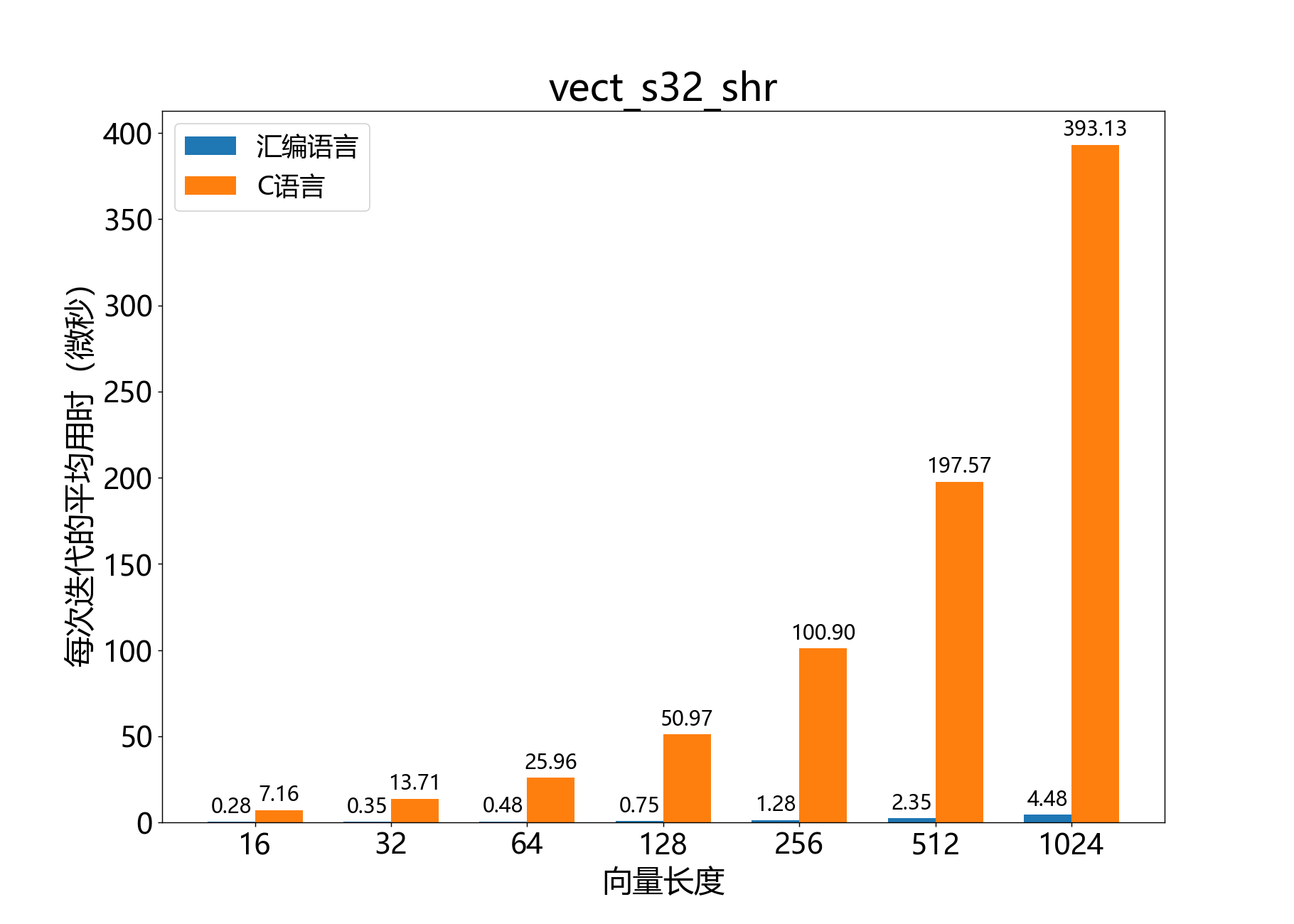
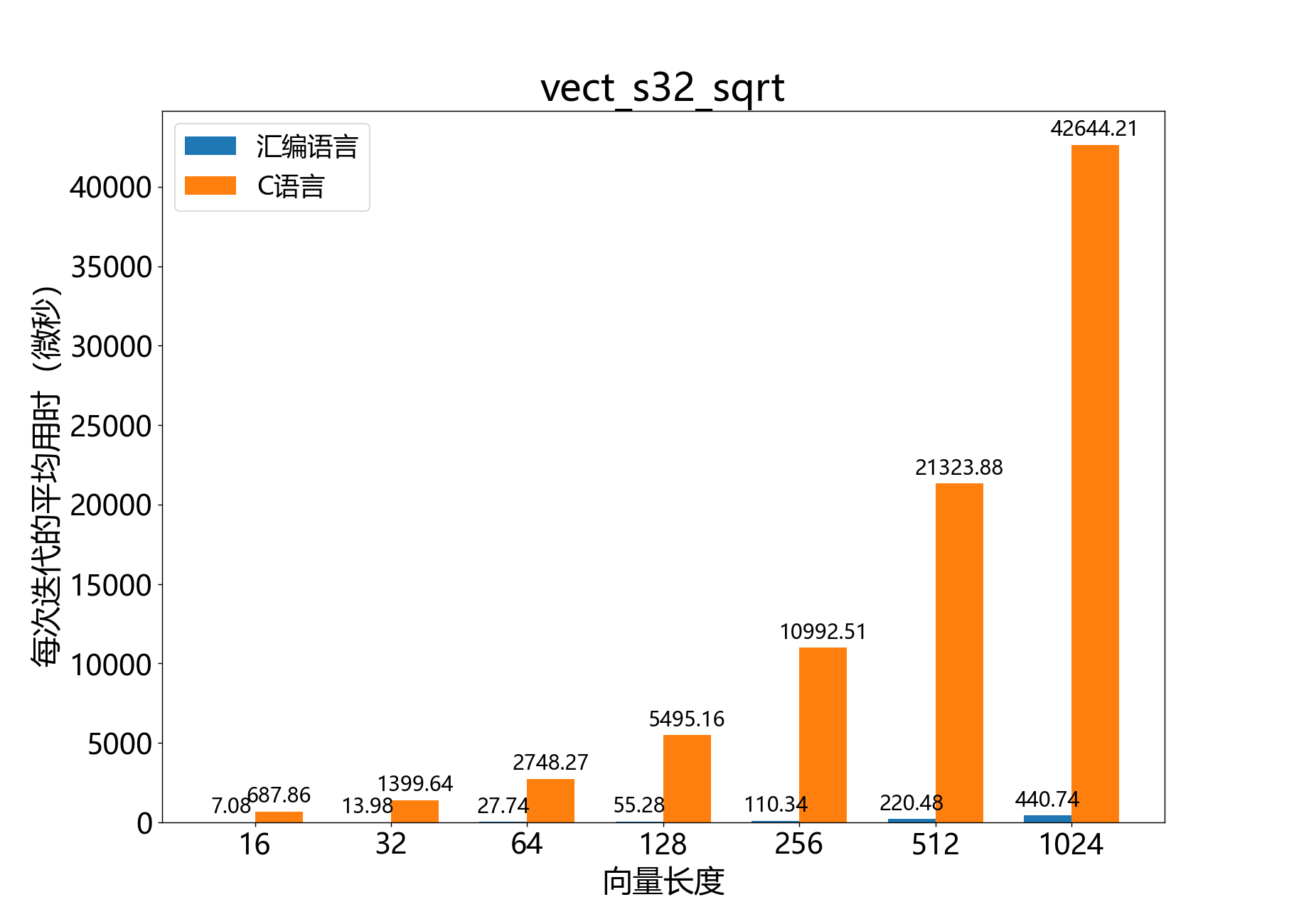
headroom_t vect_s32_sqrt()
计算32位向量元素的平方根。
a[] 和 b[] 分别表示32位尾数向量 和 。每个向量必须从对齐的地址开始。此操作可以在 b[] 上安全地原地执行。
length 是每�个向量中的元素数量。
b_shr 是应用于 的有符号算术右移。
depth 是要计算的每个 的最高有效位数。例如,depth 值为8将只计算结果的8个最高有效字节,其余3个字节为0。此参数的最大值为 VECT_SQRT_S32_MAX_DEPTH(31)。此操作的时间成本大致与计算的位数成正比。
操作:
块浮点数:
如果 是 BFP 向量 的尾数,则结果向量 是 BFP 向量 的尾数,其中 。
请注意,由于指数必须是整数,这意味着 必须是偶数。
可以使用函数 vect_s32_sqrt_prepare() 基于输入指数 和头空间 获取 和 的值。
参数:
int32_t a[]– [out] 输出向量const int32_t b[]– [in] 输入向量const unsigned length– [in] 向量 和 中的元素数量const right_shift_t b_shr– [in] 应用于 的右移量const unsigned depth– [in] 要计算的每个输出值的位数
返回值:
输出向量 的头空间(headroom)
异常:
如果 a 或 b 的地址未对齐,则引发 ET_LOAD_STORE 异常
参考性能:
headroom_t vect_s32_sub()
从一个32位向量中减去另一个32位向量。
a[]、b[]和c[]分别表示32位尾数向量、和。每个向量必须从字对齐的地址开始。此操作可以在b[]或c[]上安全地原地执行。
length是向量中的元素数量。
b_shr和c_shr是分别应用于和的有符号算术右移。
操作:
块浮点数:
如果和是BFP向量和的尾数,则结果向量是BFP向量的尾数。
在这种情况下,必须选择和,使得。只有当尾数关联到相同的指数�时,才有意义地加减尾数。
可以使用函数vect_s32_sub_prepare()根据输入指数和以及输入头空间和来获得、和的值。
参数:
-
int32_t a[]– [out] 输出向量 -
const int32_t b[]– [in] 输入向量 -
const int32_t c[]– [in] 输入向量 -
const unsigned length– [in] 向量、和中的元素数量 -
const right_shift_t b_shr– [in] 应用于的右移量 -
const right_shift_t c_shr– [in] 应用于的右移量
返回值:
- 输出向量的头空间
异常:
- 如果
a、b或c的地址不是字对齐的(参见笔记:向量对齐),则引发ET_LOAD_STORE异常。
参见:
- vect_s32_sub_prepare
参考性能:
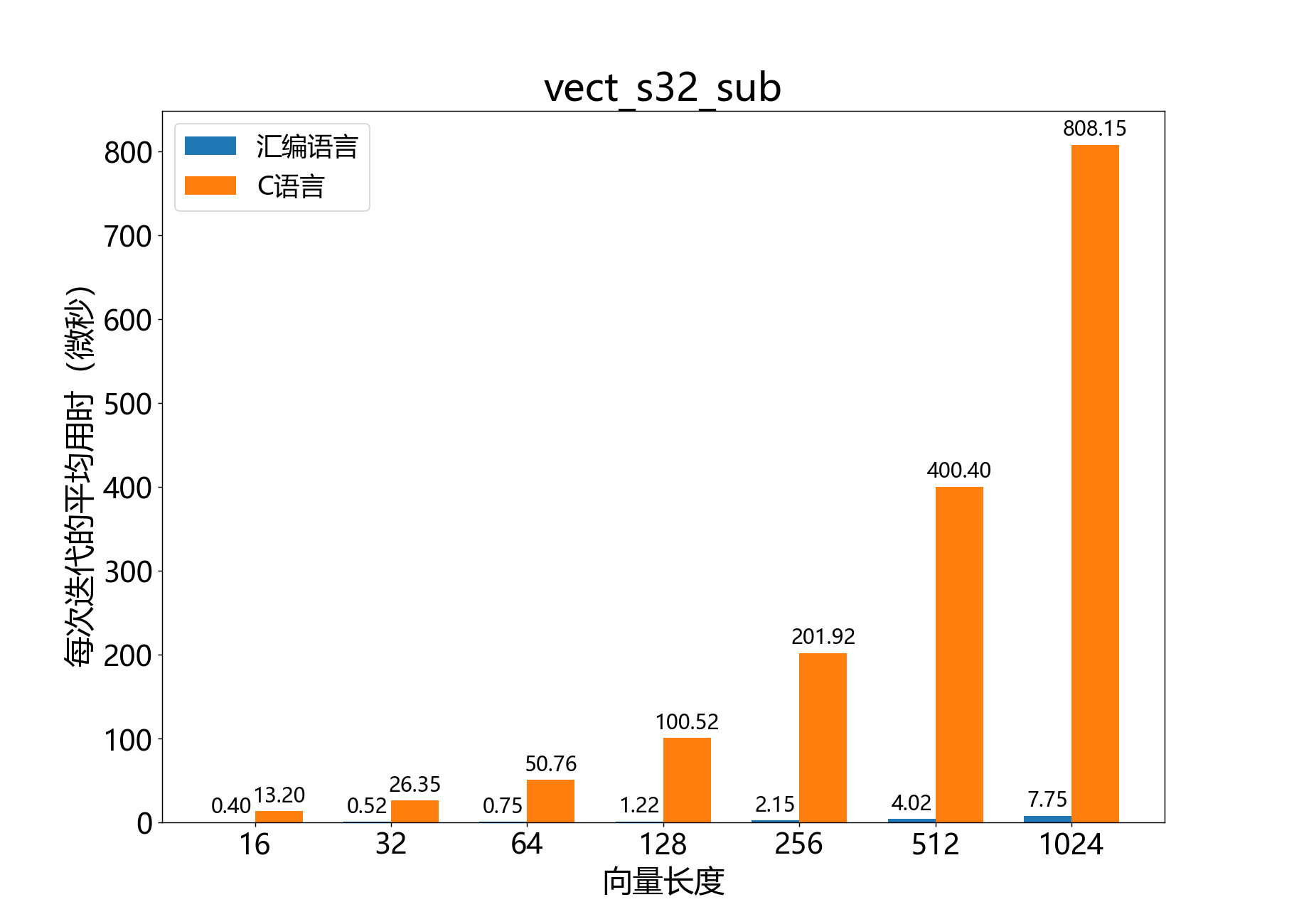
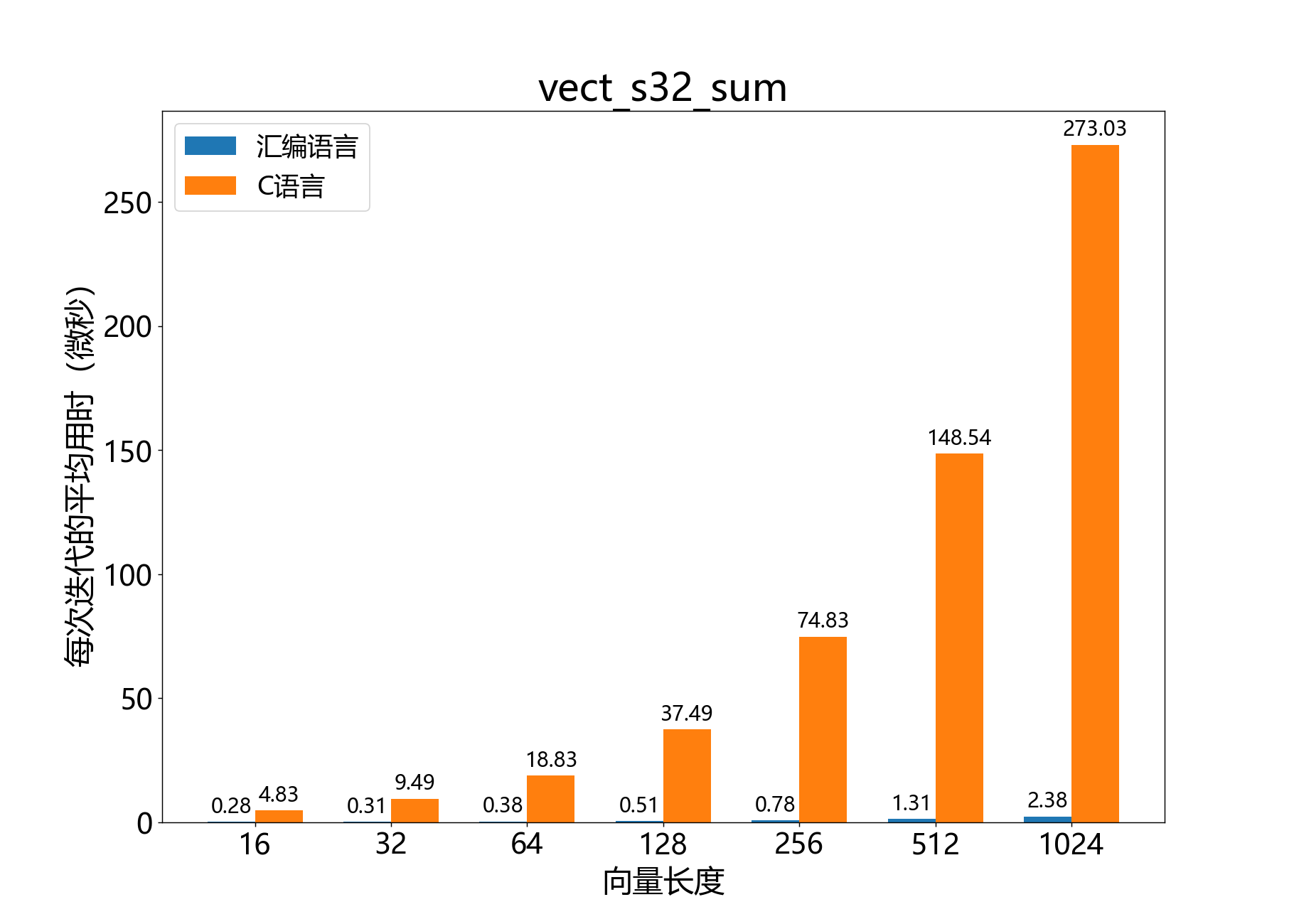
int64_t vect_s32_sum()
求32位向量的元素和。
b[]表示32位尾数向量。b[]必须从字对齐的地址开始。
length是中的元素数量。
操作:
块浮点数:
如果是BFP向量的尾数,则返回值是浮点数的64位尾数,其中。
附加细节:
在内部,每个元素累加到八个40位累加器之一(同时使用),每个值添加时应用对称的40位饱和逻辑(边界约为)。所采用的饱和算术不是可结合的,并且在中间步骤发生饱和时不会给出指示。为了避免饱和错误的可能性,length应不大于,其中是的头空间。
如果调用者的尾数向量比这个更长,可以对输入的子序列多次调用此函数以获得完整的结果,并在用户代码中将结果相加。
在许多情况下,调用者可能有先验知识表明饱和是不可能的(或几乎不可能的),在这种情况下,可以忽略此准则。然而,这些情况是特定于应用程序的,并且远远超出了本文档的范围,因此由用户自行决定。
参数:
-
const int32_t b[]– [in] 输入向量 -
const unsigned length– [in] 向量中的元素数量
返回值:
- 和的64位尾数,。
异常:
ET_LOAD_STORE如果b的地址不是字对齐的(参见笔记:��向量对齐)
参考性能:
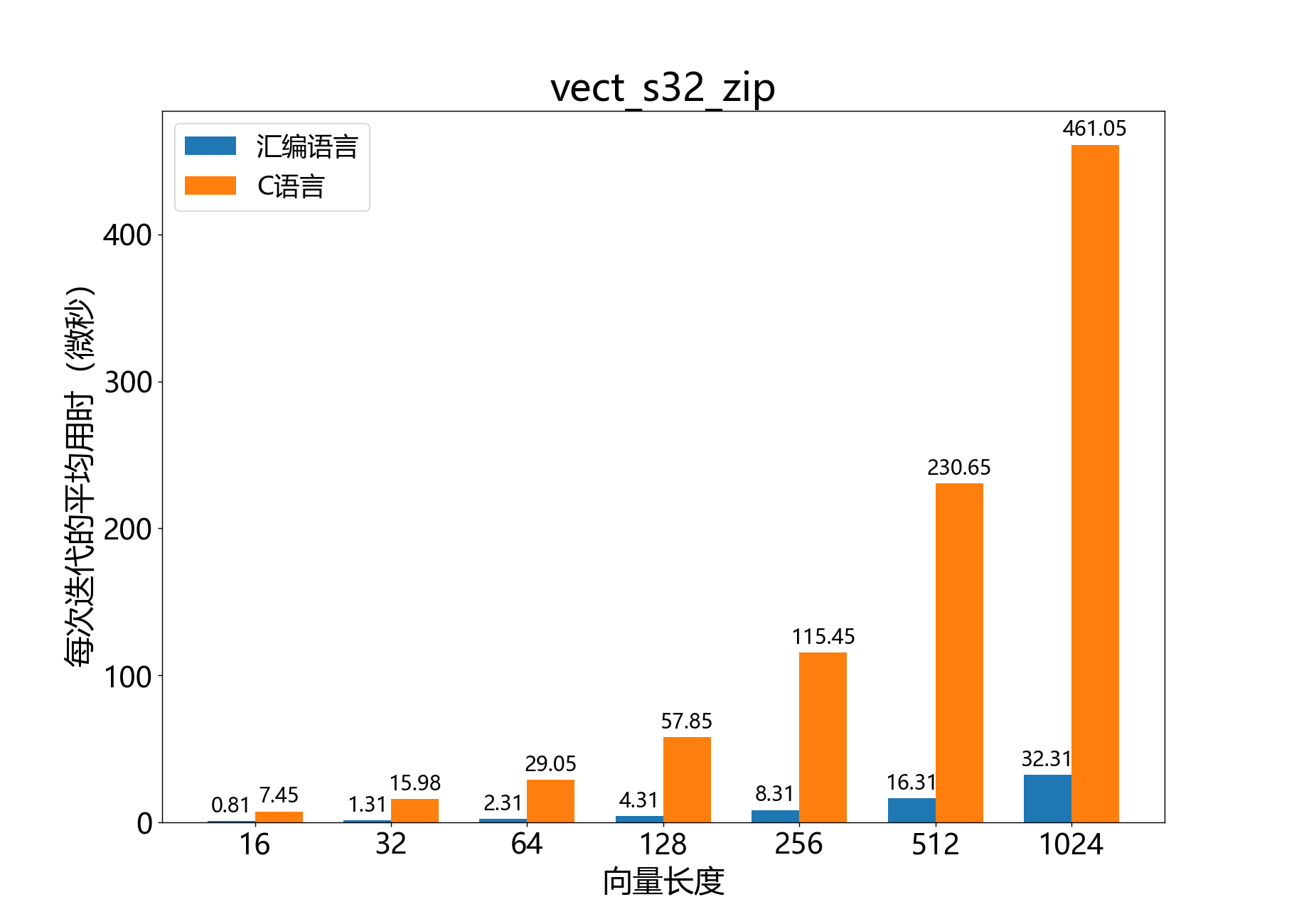
void vect_s32_zip()
将两个向量的元素交错组合成一个单一的向量。
将32位输入向量 和 的元素交错存储到32位输出向量 中。 的每个元素都右移 位, 的每个元素都右移 位。
或者(等价地),可以将此函数理解为将两个实数向量 和 组合成一个新的复数向量 ,其中 。
如果向量 和 每个都有 个元素,则结果向量 将具有 个 int32_t 元素,或者(等价地) 个 complex_s32_t 元素(并且必须有足够的空间存储这些元素)。
的每个元素 将成为 的第 个元素(应用了位移)。 的每个元素 将成为 的第 个元素。
参数:
-
complex_s32_t a[]– [out] 输出向量 -
const int32_t b[]– [in] 输入向量 -
const int32_t c[]– [in] 输入向量 -
const unsigned length– [in] 向量 、 和 中的元素数量 -
const right_shift_t b_shr– [in] 应用于 元素的有符号算术右移位数 -
const right_shift_t c_shr– [in] 应用于 元素的有符号算术右移位数
异常:
ET_LOAD_STORE如果a、b或c的对齐不是双字对齐(参见 笔记:向量对齐)
参考性能:
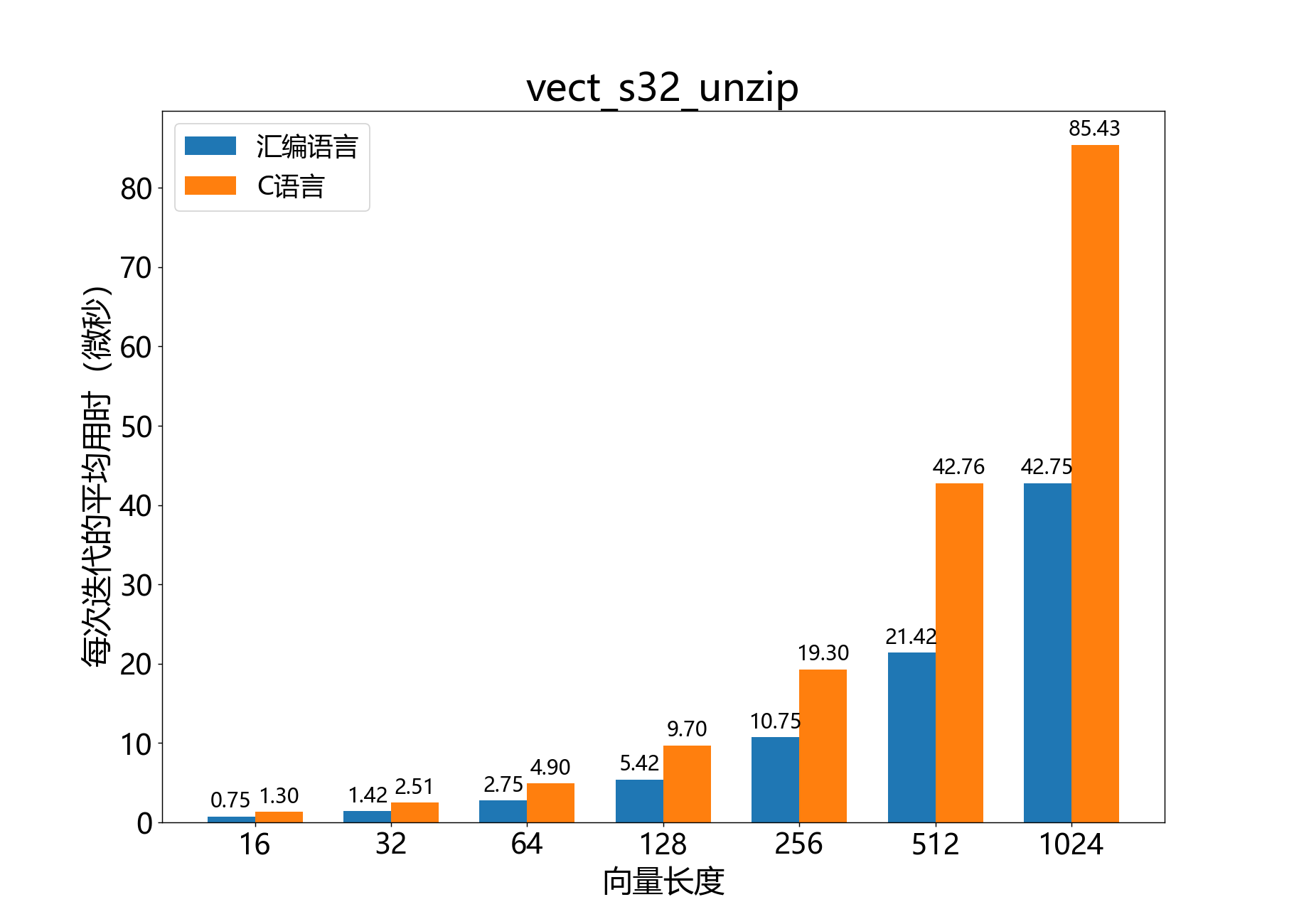
void vect_s32_unzip()
将复数32位向量的实部和虚部分离成两个单独的向量。
复数32位输入向量 的实部和虚部(如果重新解释为 int32_t 数组,则对应于偶数和奇数索引的元素)被拆分为实数32位输出向量 和 ,使得 和 。
参数:
-
int32_t a[]– [out] 输出向量 -
int32_t b[]– [out] 输出向量 -
const complex_s32_t c[]– [in] 输入向量 -
const unsigned length– [in] 向量 、 和 中的元素数量
异常:
参考性能:
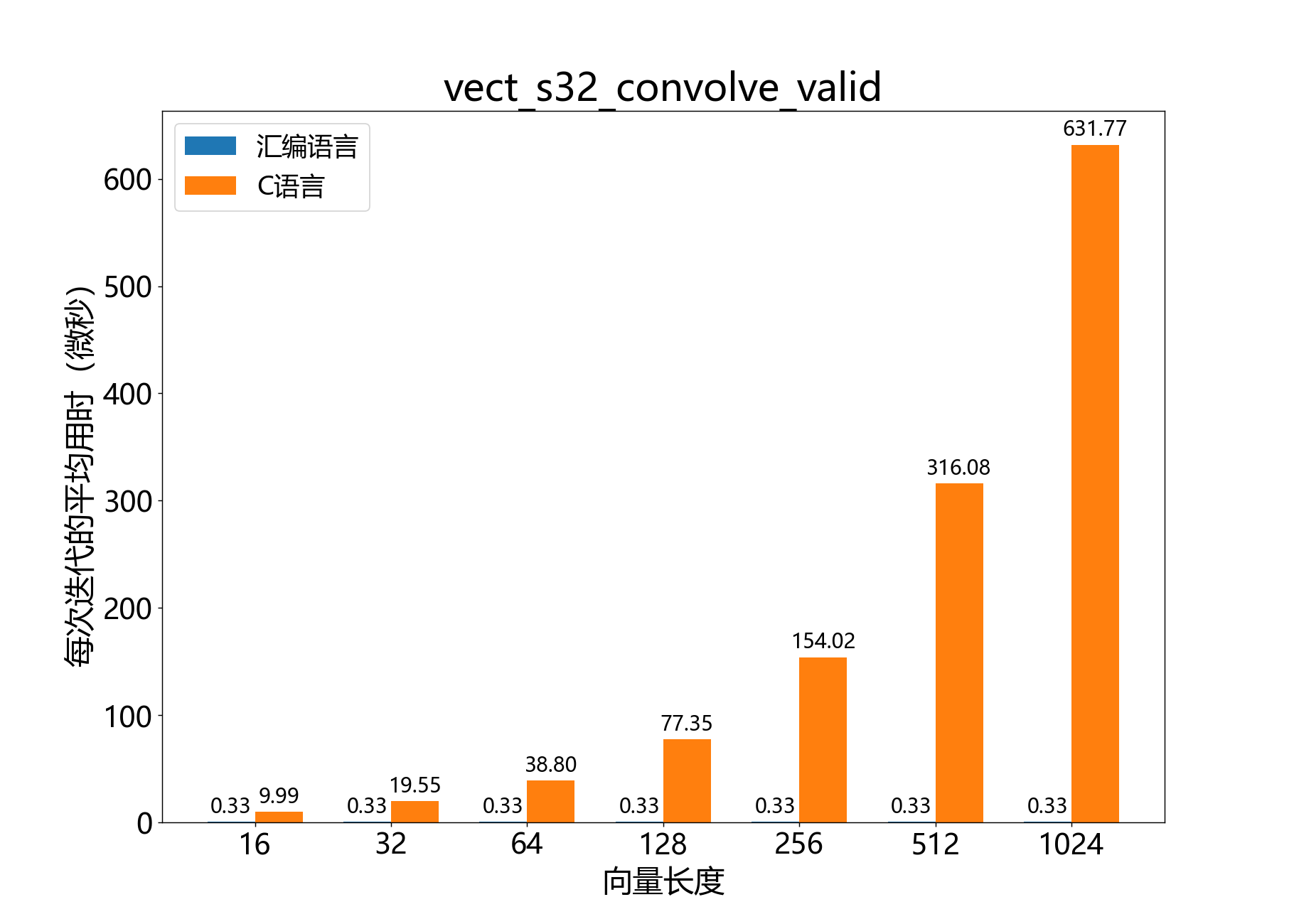
headroom_t vect_s32_convolve_valid()
将32位向量与短核进行卷积。
将32位输��入向量 与短定点核 进行卷积,得到32位输出向量 。换句话说,该函数将给定的系数为 的阶FIR滤波器应用于输入信号 。卷积是“有效”的,意味着在滤波器延伸超出输入向量边界的位置不会产生输出元素,从而导致输出向量 的元素数量减少。
此函数支持的最大滤波器阶数 为 。
参数:
-
int32_t y[]– [out] 输出向量 。如果输入 具有 个元素,并且滤波器有 个元素,则 具有 个元素,其中 。 -
const int32_t x[]– [in] 输入向量 ,长度为 。 -
const int32_t b_q30[]– [in] 滤波器系数向量 。 的系数以 Q2.30 定点格式编码。第 个系数的有效值为 。 -
const unsigned x_length– [in] 向量 中的元素数量 -
const unsigned b_length– [in] 向量 中的元素数量
异常:
ET_LOAD_STORE如果x、y或b_q30的对齐不是字对齐(参见 笔记:向量对齐)
参考性能:
pad_mode_e
卷积中支持的填充模式,用于"same"模式下的卷积。
参见:vect_s32_convolve_same(),bfp_s32_convolve_same()。
枚举包括:
-
PAD_MODE_REFLECT = (INT32_MAX-0)向量在边界处反射,即
例如,如果输入向量 的长度 为 ,滤波器的阶数 为 ,则
注意,按照惯例, 的第一个元素被认为是索引为 的元素,其中 。
-
PAD_MODE_EXTEND = (INT32_MAX-1)向量使用边界元素的值进行填充。
例如,如果输入向量 的长度 为 ,滤波器的阶数 为 ,则
注意,按照惯例, 的第一个元素被认为是索引为 的元素,其中 。
-
PAD_MODE_ZERO = 0向量使用零进行填充。
例如,如果输入向量 的长度 为 ,滤波器的阶数 为 ,则
注意,按照惯例, 的第一个元素被认为是索引为 的元素,其中 。
headroom_t vect_s32_convolve_same()
将32位向量与短核进行卷积。
将32位输入向量 与短定点核 进行卷积,得到32位输出向量 。卷积模式为"same",即输入向量被有效地填充,使得输入向量和输出向量具有相同的长度。填充行为由pad_mode_e中的某个值确定。
该函数支持的最大滤波器阶数 为 。
y[] 和 x[] 分别为输出向量 和输入向量 。
b_q30[] 为滤波器系数向量 。 的系数以 Q2.30 定点格式进行编码。第 个系数的有效值为 。
x_length 为向量 和 的元素个数 。
b_length 为向量 的长度 (即滤波器的阶数)。b_length 必须是 中的一个。
padding_mode 为 pad_mode_e 枚举中的一个值。填充模式指示了滤波器延伸到输入向量 边界之外的滤波器输入值。
参数:
-
int32_t y[]– [out] 输出向量 -
const int32_t x[]– [in] 输入向量 -
const int32_t b_q30[]– [in] 滤波器系数向量 -
const unsigned x_length– [in] 向量 的元素个数 -
const unsigned b_length– [in] 向量 的元素个数 -
const pad_mode_e padding_mode– [in] 在信号边界处应用的填充模式
void vect_s32_merge_accs()
将一组分离的32位累加器合并为int32_t向量。
将split_acc_s32_t向量转换为int32_t向量。当一个函数(例如mat_mul_s8_x_s8_yield_s32)以XS3 VPU的本地分离的32位格式输出一组累加器时,其中每个累加器的上半部分位于前32字节,下半部分位于后续32字节。
当length是16的倍数时,该函数的效率最高(以每个累加器的周期计算)。无论如何,length都会向上取整,以便始终合并16的倍数个累加器。
该函数可以安全地原地合并累加器。
参数:
-
int32_t a[]– [out] 输出的int32_t向量 -
const split_acc_s32_t b[]– [in] 输入的split_acc_s32_t向量 -
const unsigned length– [in] 要合并的累加器的数量
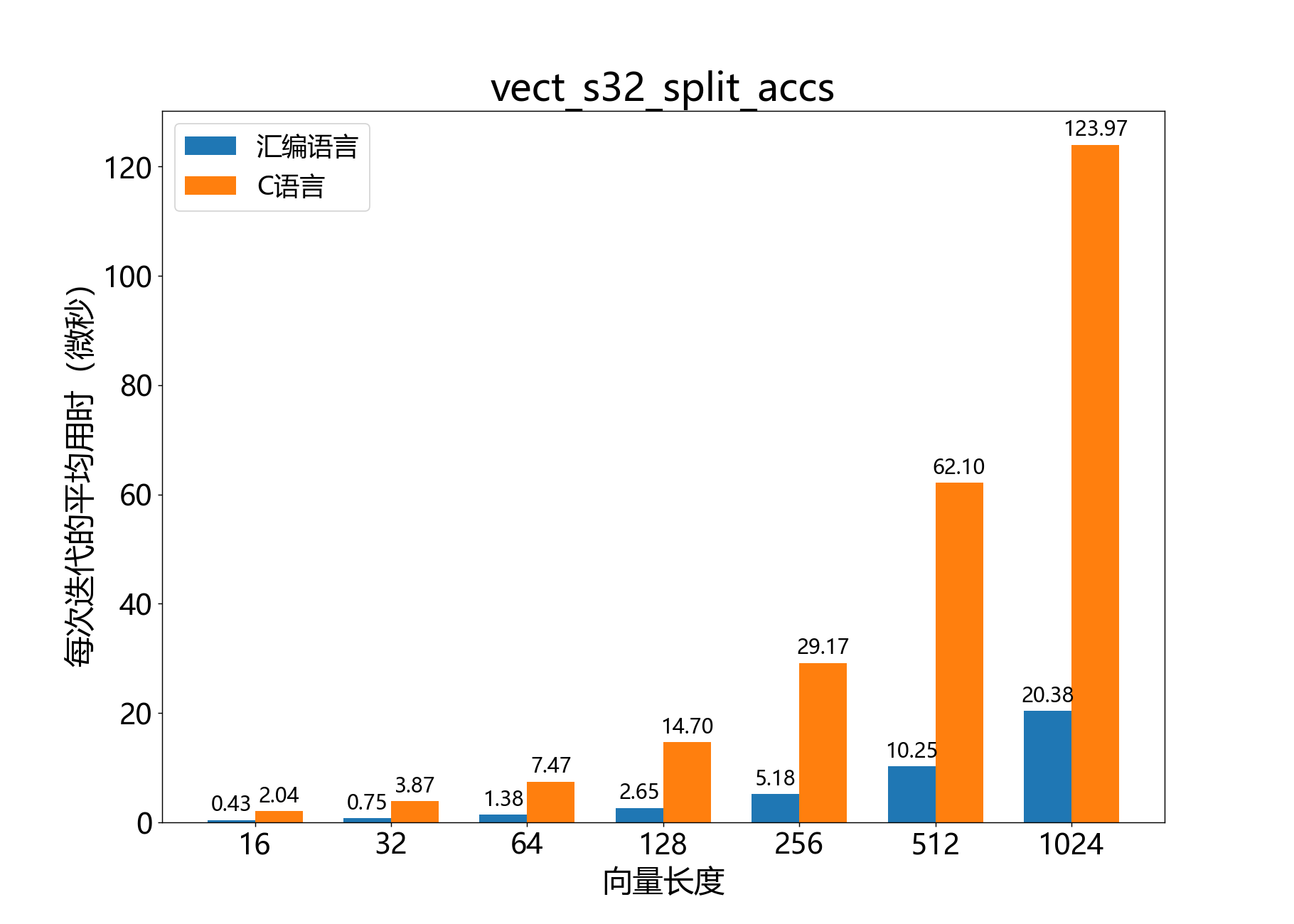
void vect_s32_split_accs()
将一个int32_t向量拆分为一个split_acc_s32_t向量。
该函数将一个int32_t向量转换为XS3 VPU的32位累加器的本机格式split_acc_s32_t向量。当一个函数(例如mat_mul_s8_x_s8_yield_s32)接收本机格式的累加器向量时,这将非常��有用。
当length是16的倍数时,此函数最高效(以循环/累加器计)。无论如何,length将向上取整,以确保总是拆分为16的倍数个累加器。
此函数可以安全地原地拆分累加器。
参数:
split_acc_s32_t a[]– [out] 输出的split_acc_s32_t向量const int32_t b[]– [in] 输入的int32_t向量const unsigned length– [in] 需要拆分的累加器数量
参考性能:
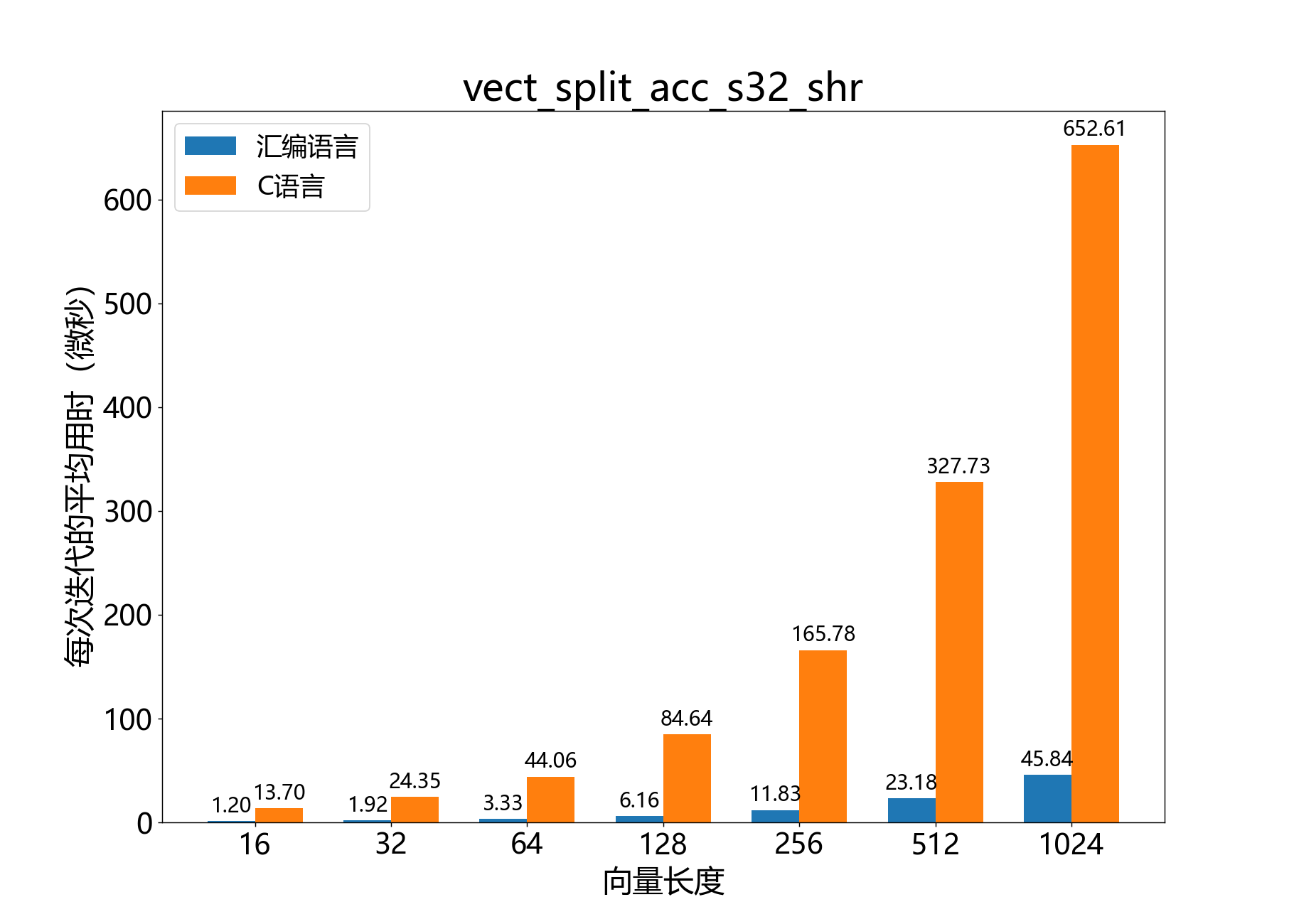
void vect_split_acc_s32_shr()
对32位拆分累加器向量的元素进行右移操作。
此函数可以与chunk_s16_accumulate()或bfp_s16_accumulate()结合使用,以避免累加器的饱和。
此函数会原地更新。
参数:
split_acc_s32_t a[]– [inout] 累加器向量const unsigned length– [in] 的元素数量const right_shift_t shr– [in] 对 的元素进行右移的位数
参考性能:
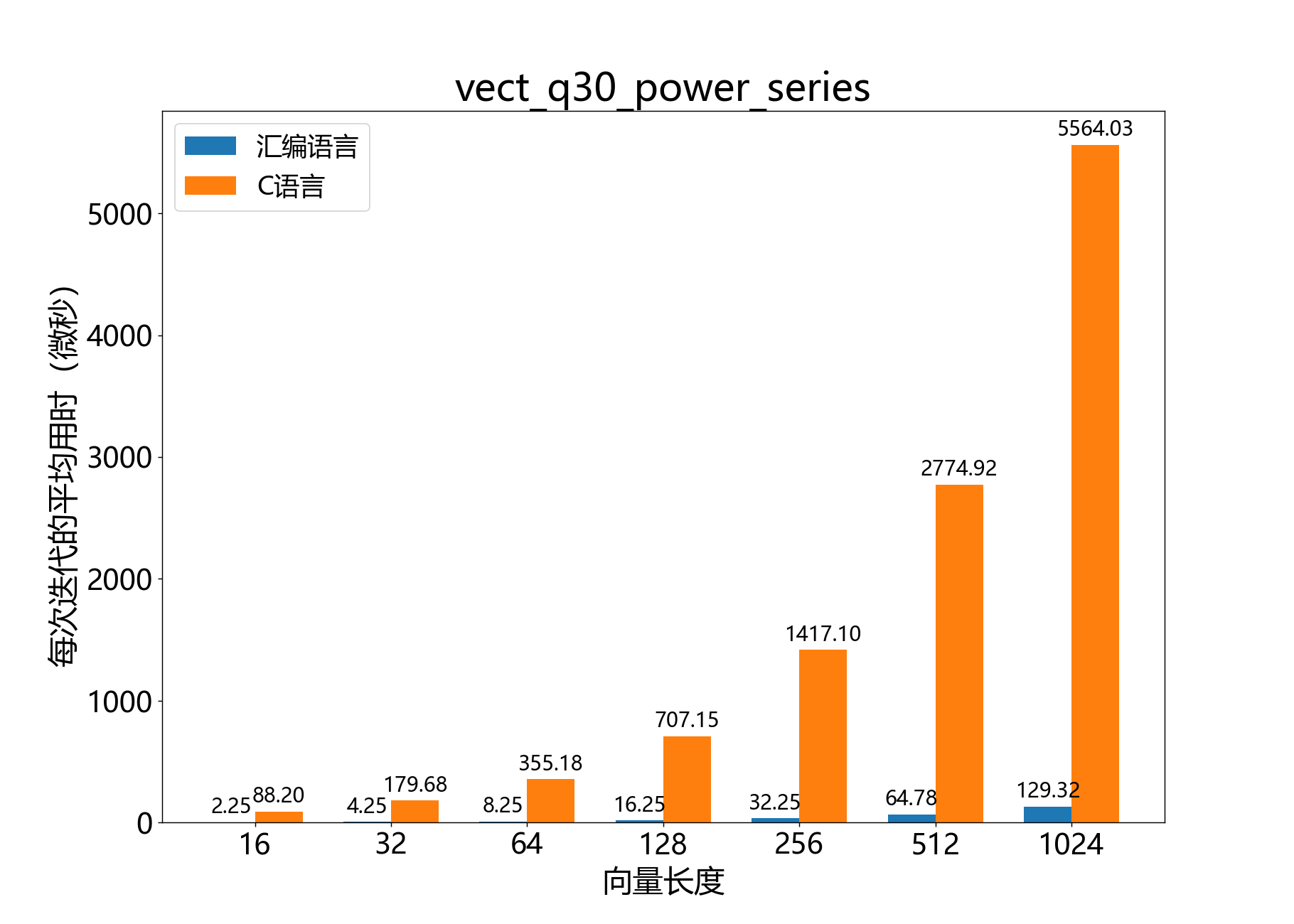
void vect_q30_power_series()
计算Q2.30值向量的幂级数和。
该函数用于计算Q2.30值向量 的幂级数和。 包含Q2.30值, 是一个包含与 的幂级数相乘的系数的向量,可以具有任意的关联指数。输出是向量 ,其指数与 相同。
参数:
int32_t a[]– [out] 输出向量const q2_30 b[]– [in] 输入向量const int32_t c[]– [in] 系数向量const unsigned term_count– [in] 幂级数项数,const unsigned length– [in] 向量 和 中的元素数量
参考性能:
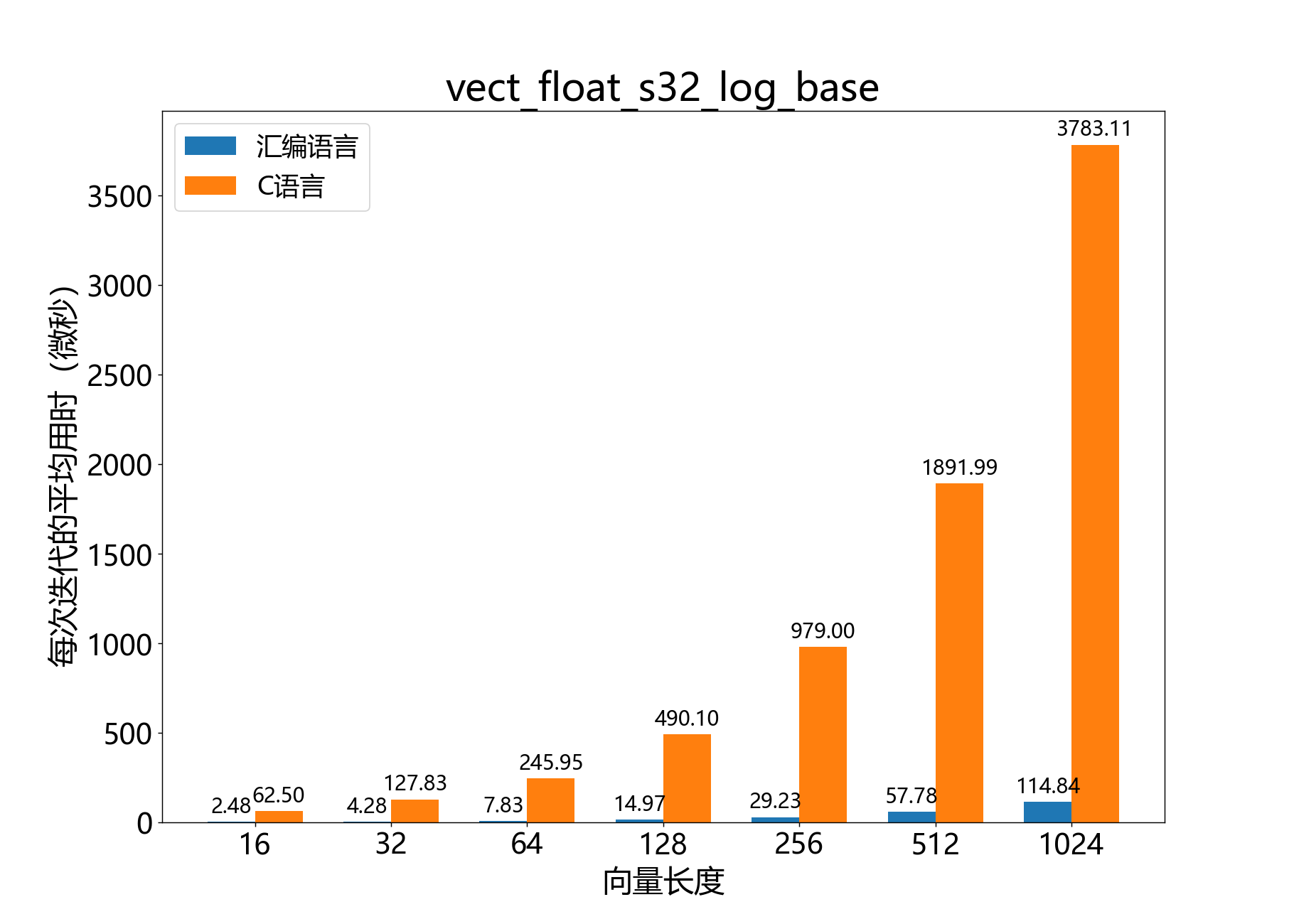
void vect_float_s32_log_base()
计算float_s32_t向量的以指定底数为基数的对数。
该函数计算float_s32_t值向量 的对数。计算的对数的底数由参数 inv_ln_base_q30 指定。结果写入输出向量 ,它是一个Q8.24格式的向量。
参数:
q8_24 a[]– [out] 输出的Q8.24格式的向量const float_s32_t b[]– [in] 输入的向量const q2_30 inv_ln_base_q30– [in] 系数 ,用于从自然对数转换为所需底数const unsigned length– [in] 向量 和 中的元素数量
参考性能:
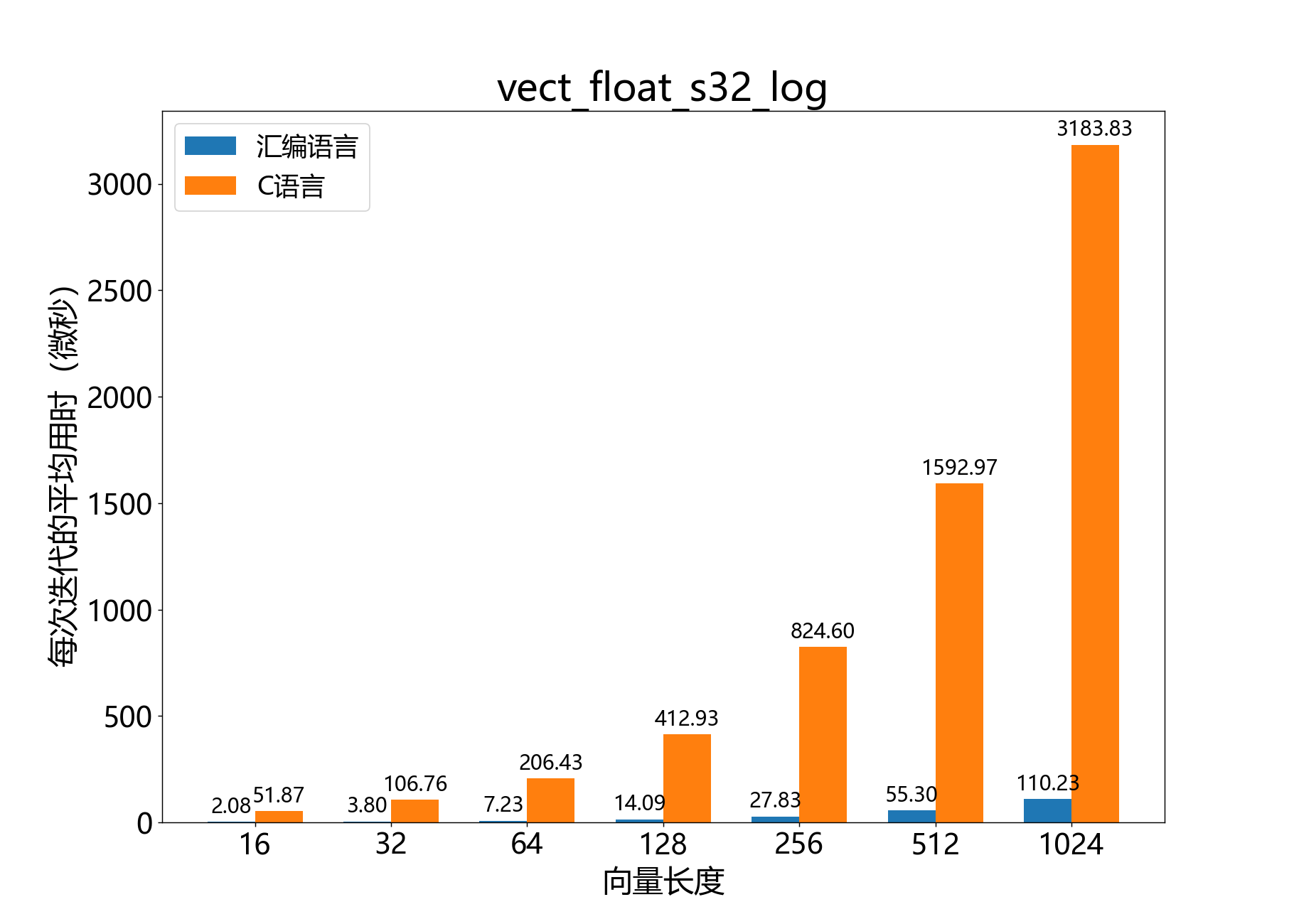
void vect_float_s32_log()
计算float_s32_t向量的自然对数。
该函数计算float_s32_t值向量 的自然对数。结果写入输出向量 ,它是一个Q8.24格式的向量。
参数:
q8_24 a[]– [out] 输出的Q8.24格式的向量const float_s32_t b[]– [in] 输入的向量const unsigned length– [in] 向量 和 中的元素数量
参考性能:
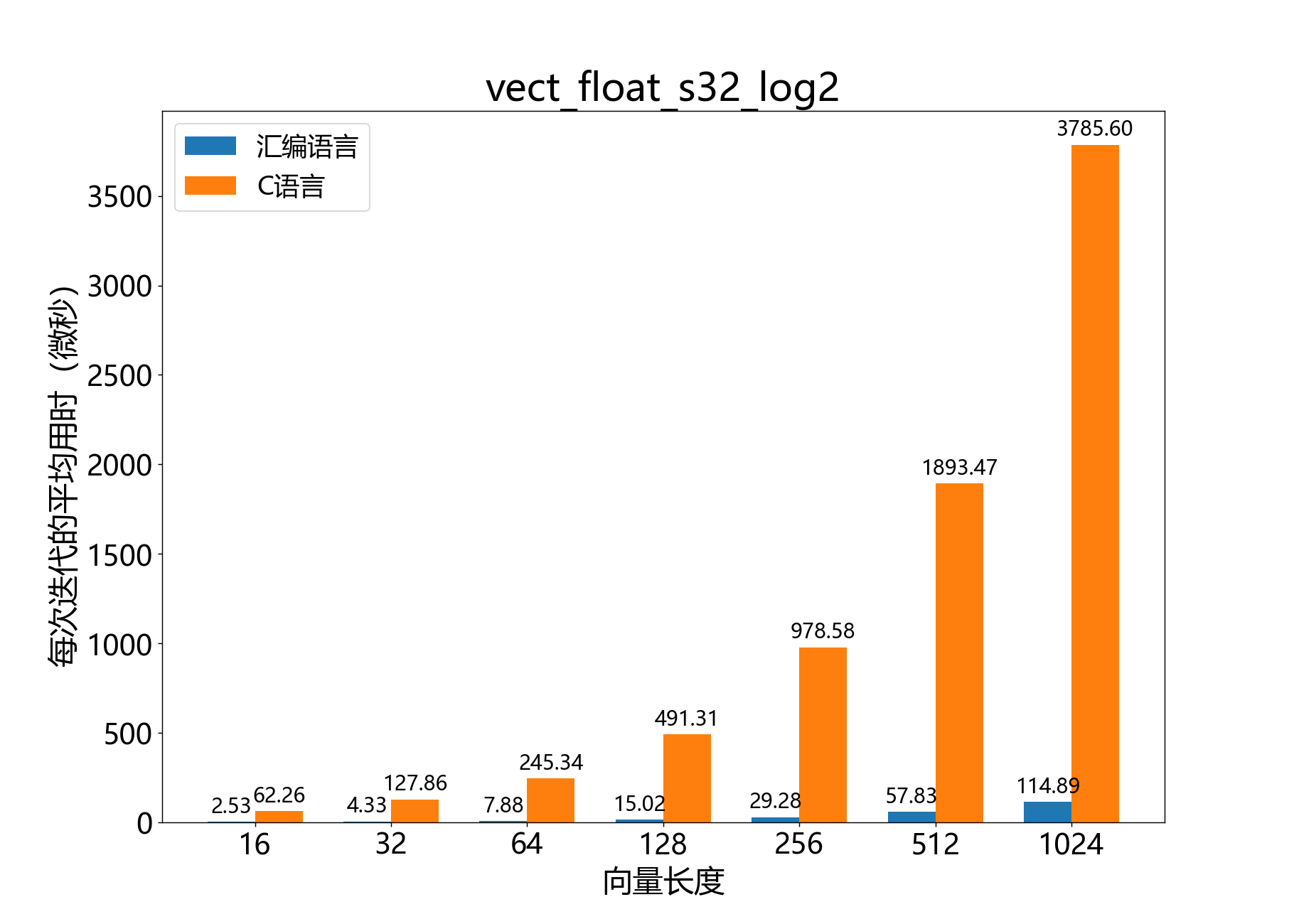
void vect_float_s32_log2()
计算float_s32_t向量的以2为底的对数。
该函数计算float_s32_t值向量 的以2为底的对数。结果写入输出向量 ,它是一个Q8.24格式的向量。
参数:
q8_24 a[]– [out] 输出的Q8.24格式的向量const float_s32_t b[]– [in] 输入的向量const unsigned length– [in] 向量 和 中的元素数量
参考性能:
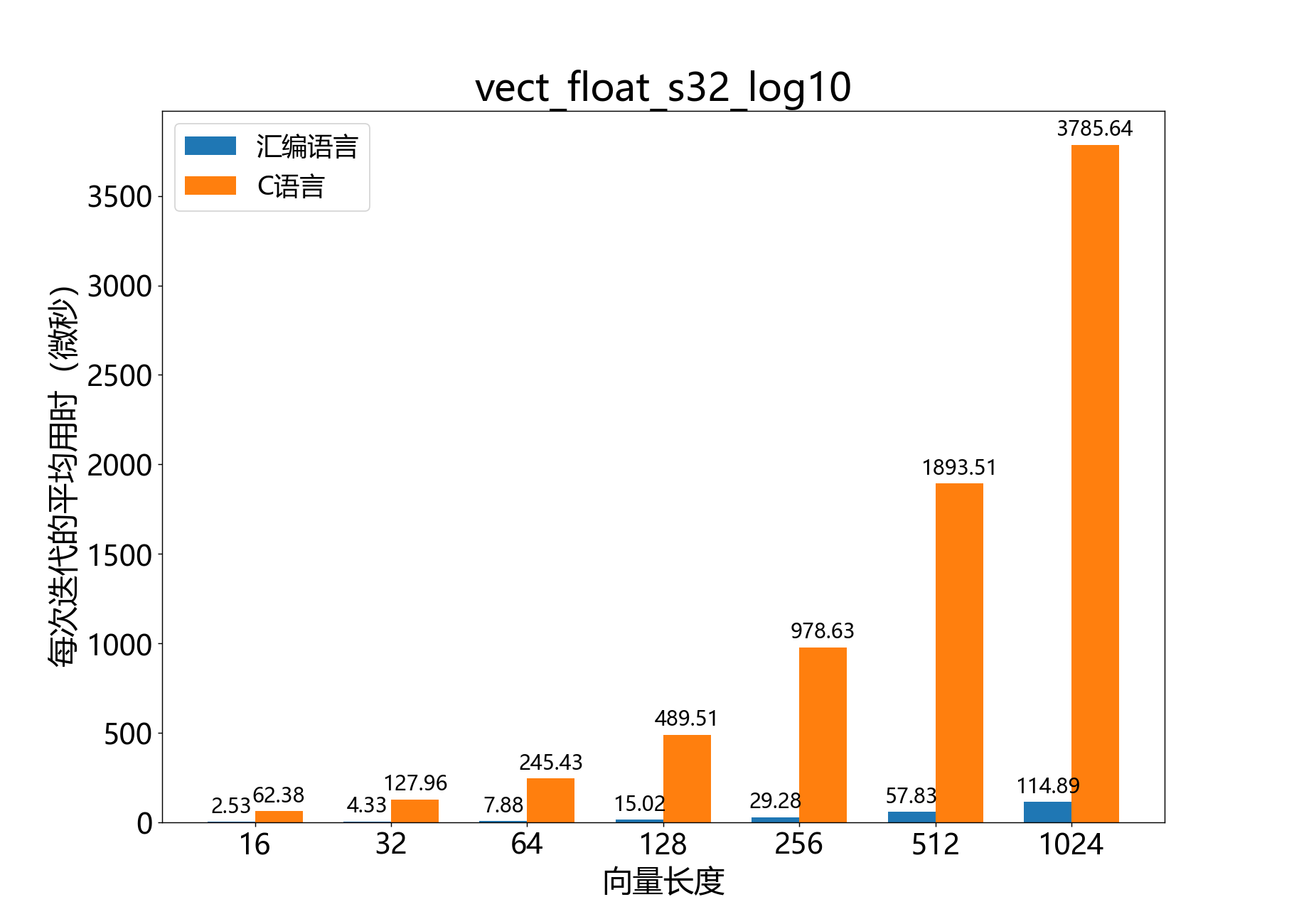
void vect_float_s32_log10()
计算float_s32_t向量的以10为底的对数。
该函数计算float_s32_t值向量 的以10为底的对数。结果写入输出向量 ,它是一个Q8.24格式的向量。
参数:
q8_24 a[]– [out] 输出的Q8.24格式的向量const float_s32_t b[]– [in] 输入的向量const unsigned length– [in] 向量 和 中的元素数量
参考性能:
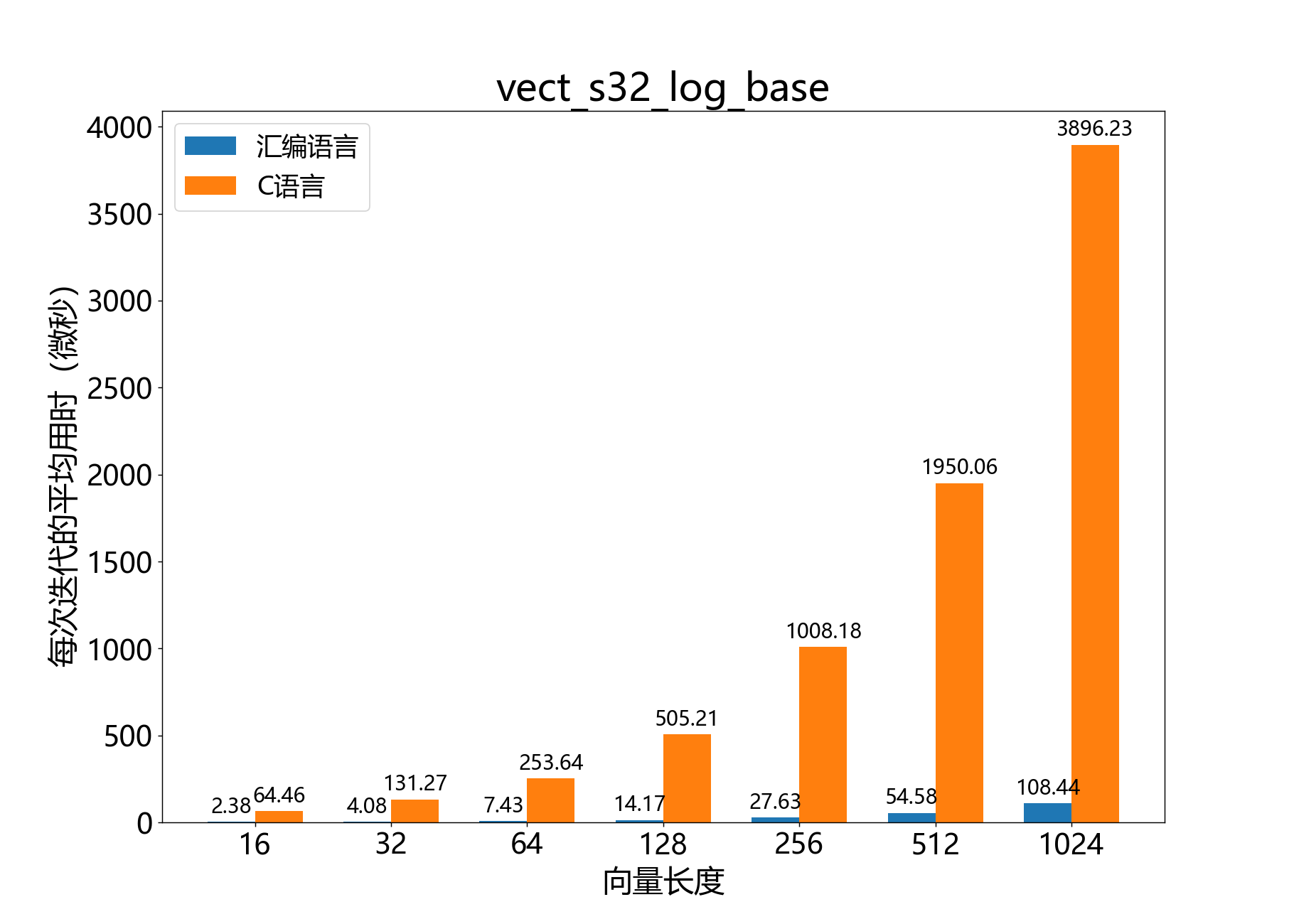
void vect_s32_log_base()
计算块浮点向量的以指定底数为底的对数。
该函数计算块浮点向量 的对数,计算所得的对数的底数由参数 inv_ln_base_q30 指定。结果将被写入输出向量 ,其中的值为 Q8.24。
如果所需的底数为 ,则 inv_ln_base_q30,在此处表示为 ,应为 。也就是说:所需底数的自然对数的倒数,以 Q2.30 的值表示。通常情况下,所需的底数在编译时已知,因此这个值通常是一个预先计算的常数。
对于 的情况,结果 是未定义的。
该操作定义如下:
参数:
q8_24 a[]– [out] 输出的 Q8.24 向量const int32_t b[]– [in] 输入的尾数向量const exponent_t b_exp– [in] 与 相关联的指数const q2_30 inv_ln_base_q30– [in] 从自然对数转换为所需底数 的系数const unsigned length– [in] 向量 和 中的元素数量
异常情况:
ET_LOAD_STORE如果b或a的双字对齐,则引发异常(参见笔记:向量对齐)
参考性能:
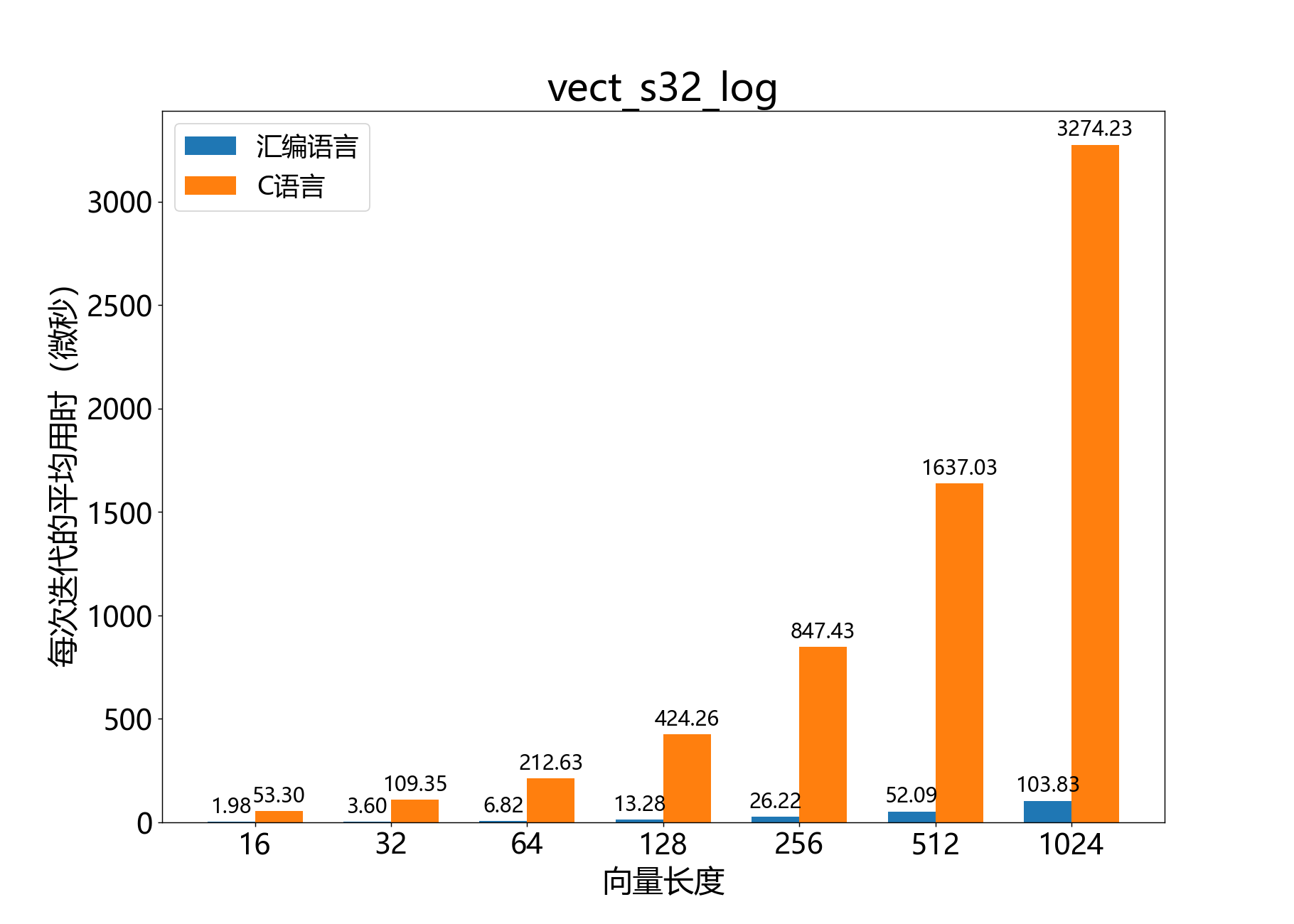
void vect_s32_log()
计算块浮点向量的自然对数。
该函数计算块浮点向量 的自然对数,结果将被写入输出向量 ,其中的值为 Q8.24。
对于 的情况,结果 是未定义的。
该操作定义如下:
�参数:
q8_24 a[]– [out] 输出的 Q8.24 向量const int32_t b[]– [in] 输入的尾数向量const exponent_t b_exp– [in] 与 相关联的指数const unsigned length– [in] 向量 和 中的元素数量
异常情况:
ET_LOAD_STORE如果b或a的双字对齐,则引发异常(参见笔记:向量对齐)
参考性能:
void vect_s32_log2()
计算块浮点向量的以 2 为底的对数。
该函数计算块浮点向量 的以 2 为底的对数,结果将被写入输出向量 ,其中的值为 Q8.24。
对于 的情况,结果 是未定义的。
该操作定义如下:
参数:
q8_24 a[]– [out] 输出的 Q8.24 向量const int32_t b[]– [in] 输入的尾数向量const exponent_t b_exp– [in] 与 相关联的指数const unsigned length– [in] 向量 和 中的元素数量
异常情况:
ET_LOAD_STORE如果b或a的双字对齐,则引发异常(参见笔记:向量对齐)
参考性能:
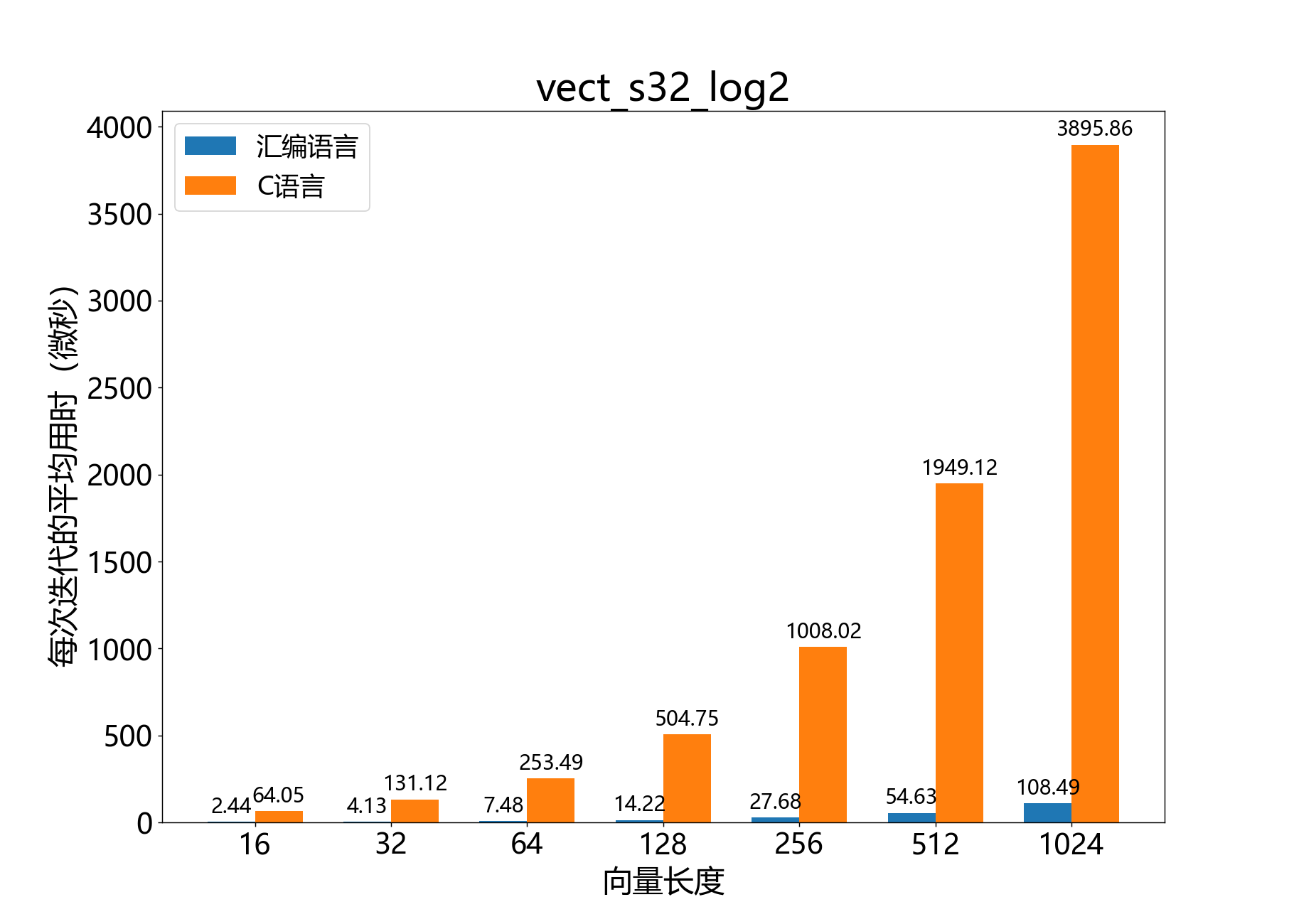
void vect_s32_log10()
计算块浮点向量的以 10 为底的对数。
该函数计算块浮点向量 的以 10 为底的对数,结果将被写入输出向量 ,其中的值为 Q8.24。
对于 的情况,结果 是未定义的。
该操作定义如下:
参数:
q8_24 a[]– [out] 输出的 Q8.24 向量const int32_t b[]– [in] 输入的尾数向量const exponent_t b_exp– [in] 与 相关联的指数const unsigned length– [in] 向量 和 中的元素数量
异常情况:
ET_LOAD_STORE如果b或a的双字对齐,则引发异常(参见笔记:向量对齐)
参考性能:
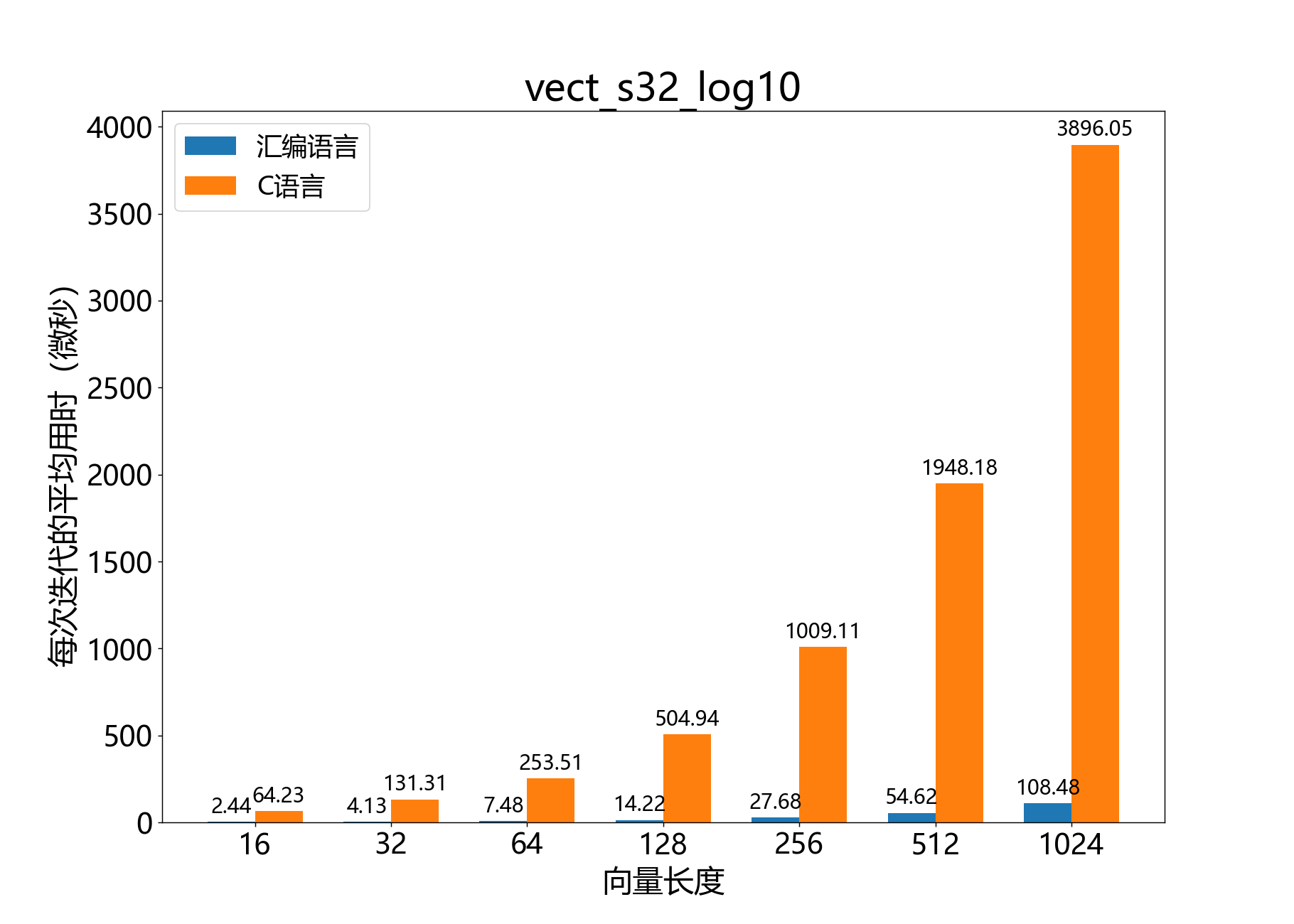
void vect_q30_exp_small()
计算接近0的Q2.30值的指数函数 。
该函数计算输入向量 中每个 的 ,并将结果作为Q2.30值放入输出向量 。
该函数用于计算在区间 内的 的指数函数 。超出该范围,误差会迅速增大。
操作:
对于 ,
参数:
-
q2_30 a[]– [out] 输出向量 -
const q2_30 b[]– [in] 输入向量 -
const unsigned length– [in] 向量 和 中的元素数量
参考性能:
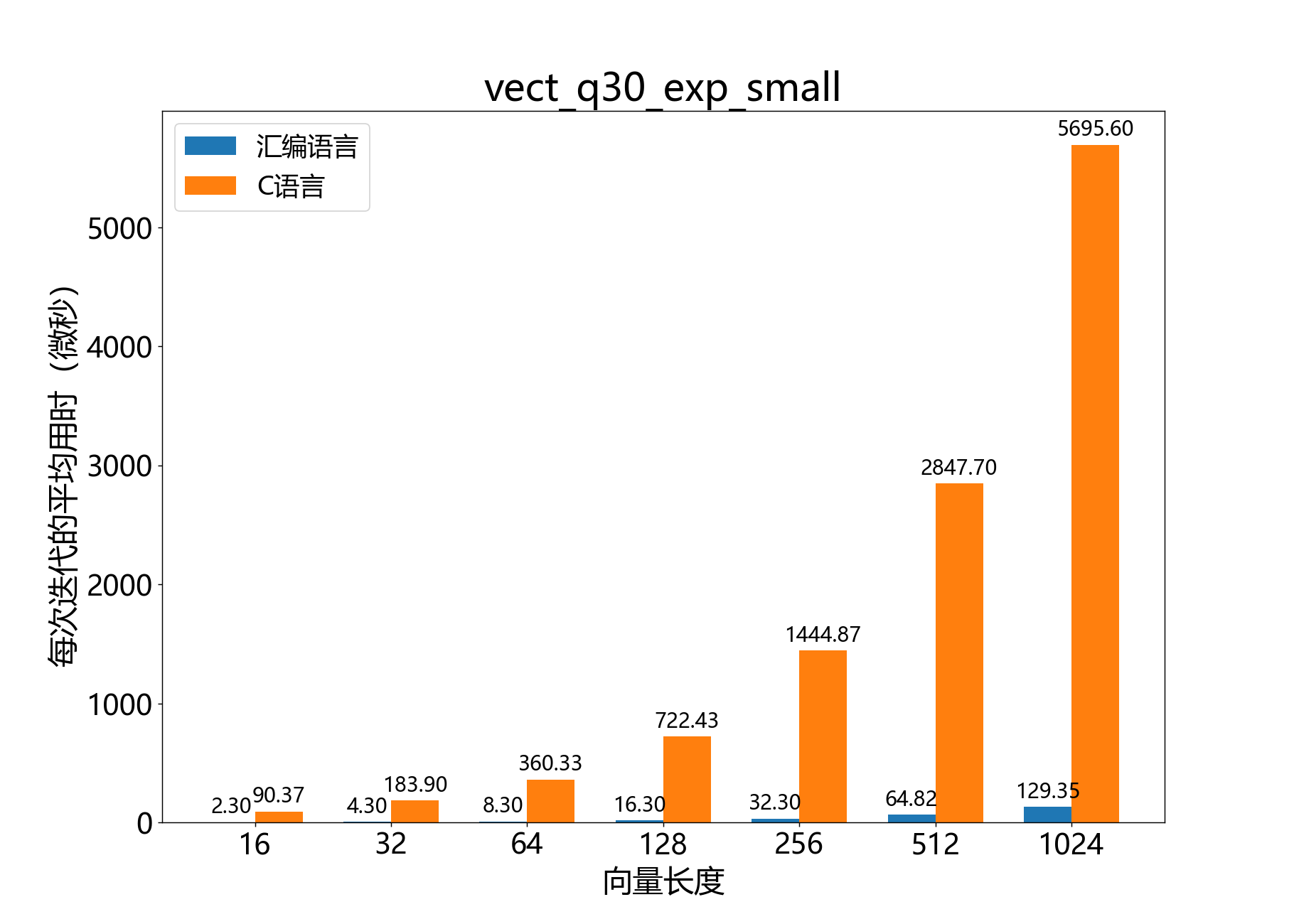
void vect_s32_to_vect_s16()
将32位向量转换为16位向量。
该函数将32位尾数向量 转换为16位尾数向量 。从概念上讲,输出BFP向量 表示与输入BFP向量 相同的值,只是位深度减小了。
在大多数情况下, 应该为 ,其中 是32位输入尾数向量 的头空间。
输出指数 由 给出。
操作:
对于 ,
参数:
-
int16_t a[]– [out] 输出向量 -
const int32_t b[]– [in] 输入向量 -
const unsigned length– [in] 向量 和 中的元素数量 -
const right_shift_t b_shr– [in] 对 进行的右移操作
参考性能:
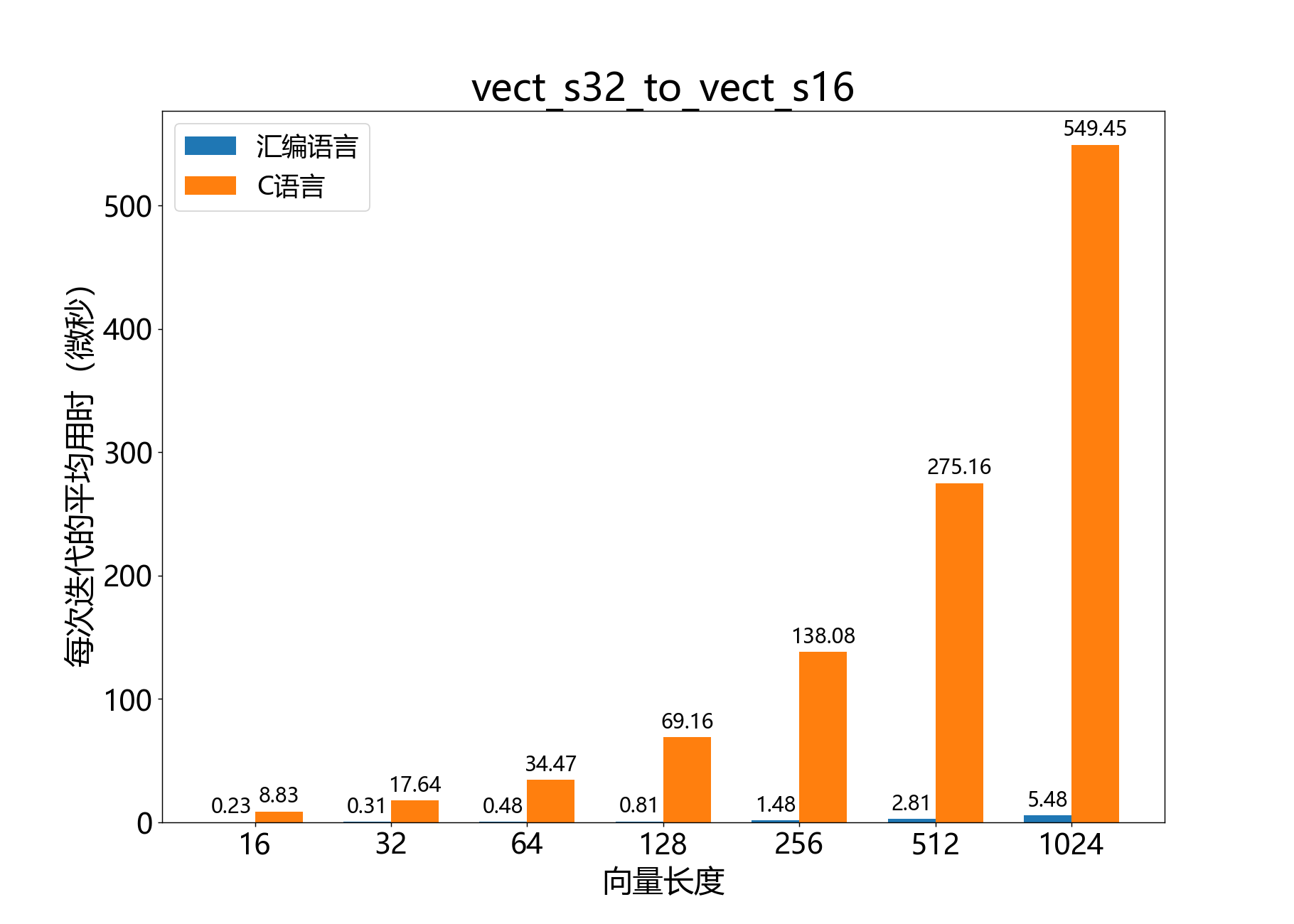
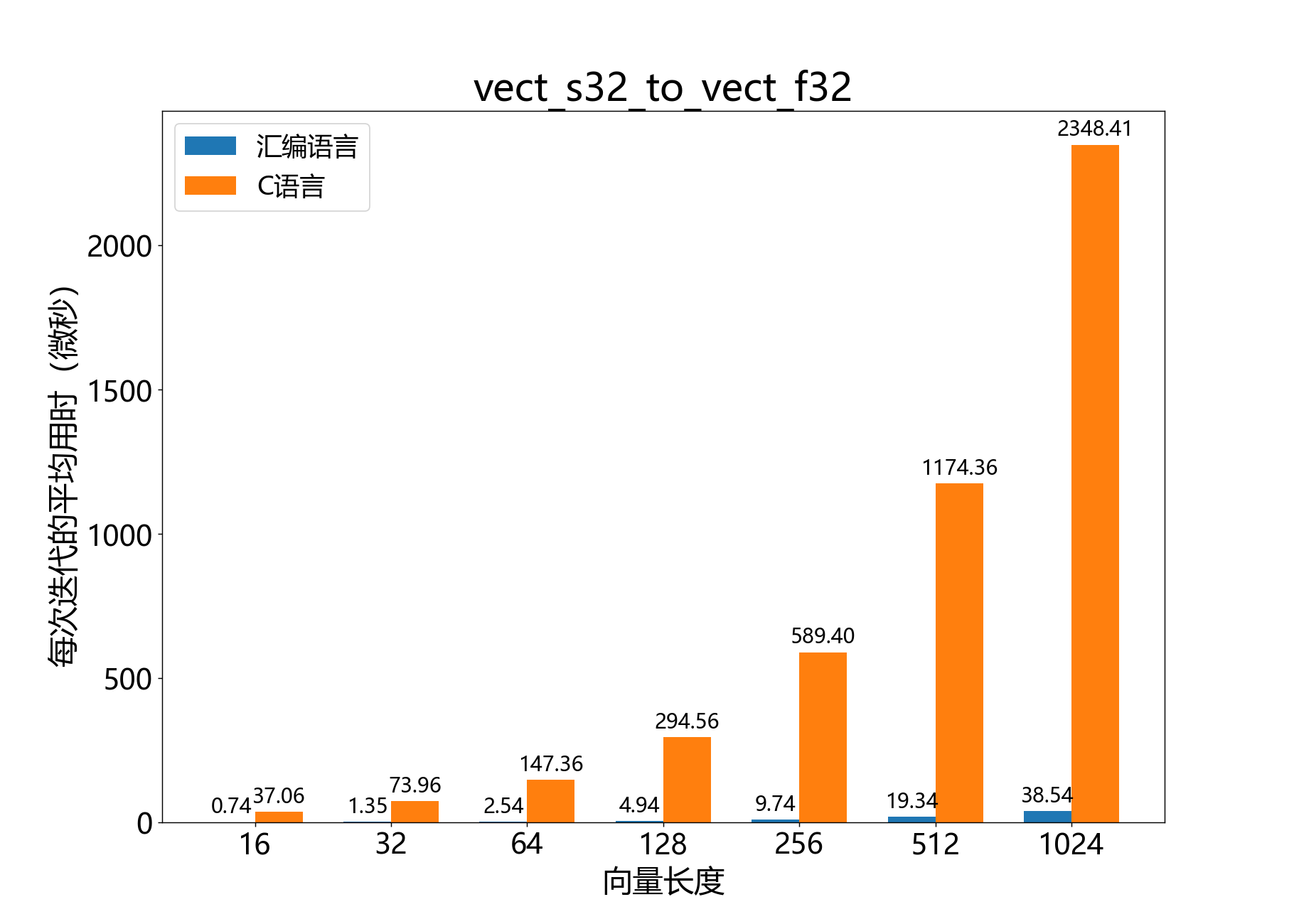
void vect_s32_to_vect_f32()
将32位BFP向量转换为IEEE754单精度浮点数向量。
该函数将32位尾数向量和指数 转换为32位IEEE754单精度浮点数元素向量 。从概念上讲,输出向量 的元素表示与输入向量相同的值。
由于IEEE754单精度浮点数的尾数位数较少,这个操作可能会导致某些元素的精度损失。
操作:
对于 ,
参数:
-
float a[]– [out] 输出IEEE754浮点数向量 -
const int32_t b[]– [in] 32位输入尾数向量 -
const unsigned length– [in] 向量 和 中的元素数量 -
const exponent_t b_exp– [in] 输入向量 的指数
参考性能: